Entities from Seznam.cz winning twice the second prize in ERDC 2014
Seznam.cz Research have participated in the Entity Recognition and Disambiguation Challenge 2014 organized by Microsoft, Yahoo!, and Google. There were two tracks in the competition, and Seznam.cz won the second prize in both of them. Linking queries and parts of documents to the entities of Wikipedia or Freebase is an important ingredient to semantic search technology.
Modern search engines need to understand the contents of web documents, the intents of user queries, and the context in which they appear. To achieve this, in some sense, they seek help in knowledge bases like Wikipedia, Freebase, Linked Data, and other open or proprietary, generic or domain-specific sources of structured information. Knowledge bases provide a useful model of our world and the entities in it—people, places, things, events, institutions, creatures, substances, concepts, … you name it.
- knowledge base
- is a conceptual network of entities and relations between them
- entity
- is something that exists by itself, in reality or in our minds
- uri
- identifies the model of an entity in a knowledge base
The objective of the Entity Recognition and Disambiguation Challenge hosted by the ACM SIGIR 2014 conference was to incite new approaches to the problem of entity linking. Participating teams were to develop systems that recognize mentions of entities in a given text, disambiguate them, i.e. remove non-relevant options by considering the context, and map them to the entities in a given entity collection or knowledge base.
The ERD Challenge included two tasks: one to find entities in search queries (Short Track), the other to find entities in texts from web pages (Long Track). We have participated in both tracks with the same system tuned to each of the tasks. In the evaluation, we reached the success rate of 71.9% on the Long Track and of 66.9% on the Short Track, scoring the third but winning the second prize in both.
In the rest of this post, let us outline the issues of these tasks and the solutions we came up with, offering more details in our paper. We recommend this entity linking and retrieval tutorial for a thorough introduction into the topic.
Long Track: entities in documents
Given a piece of text, locate the mentions of relevant entities and refer each mention to a single entity. This task is similar to, but not the same as, deciding where to put explanatory Wikipedia links if you were editing a Wikipedia page.

The figure on the right shows an example annotation of mentions (pink) and entities (blue) that a human is expecting to receive from the entity-linking system for the given text. Note that common words like smartphone or manufacturer, which do match with entities in Wikipedia, are not expected to be linked to them in this context.
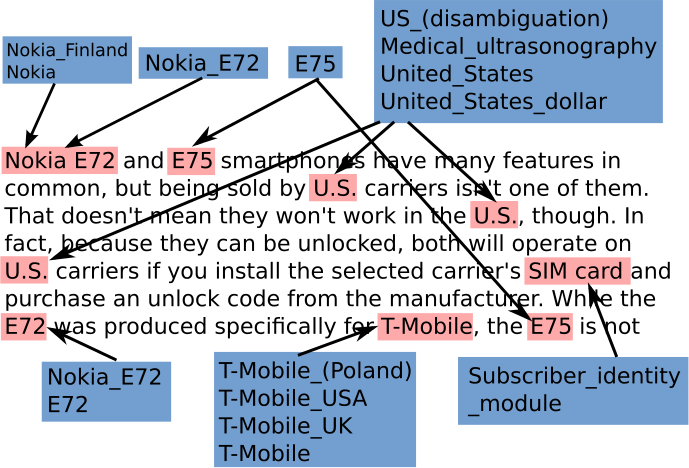
The other figure lists the entities that our system considers for disambiguation, having detected the mentions and matched them with the knowledge base. These steps must be done carefully, since we do not want to miss any entity, but having too many loosely matching entities would harm the performance of the system. The mention E75 does not suggest the correct entity, however, all of E72, Nokia, and Nokia E72 do include the right candidates. During disambiguation, we compute a score for each candidate entity, and then proceed only with the best ones. We need to handle adjacent and overlapping matches and prune the entities further in order to provide only those found in the ERDC entity collection.
The design of the scoring method is probably the most challenging part of the work, requiring creativity as well as technical insight. Our system has a modular architecture that permits easy trials of different configurations and methods. There is a few dozens of options from which we chose the best combination for the ERD Challenge. Yet, we are able to adjust our system to work with other languages and knowledge bases, and in the settings of our own search engine.
The key points of our approach to the entity linking problem include: tracing subsequent mentions, estimating mention and entity probabilities, constructing the entity co-occurrence graph and computing the rank and curvature of its nodes, and applying various heuristics for mention detection and entity pruning.
Short Track: entities in queries
Given a search query, return a set of relevant entities that are associated with it. The absence of context and the peculiar syntax of the queries both justify why the task gives up mention detection and uniqueness of the solution. Do not get me wrong. Both mention detection and disambiguation are involved in the process. They are just evaluated differently.
Consider the query berkeley square mini series. The a priori most likely entity candidate is Berkeley, California. However, there are two Berkeley Squares in England, and other matching entities. Yet, thanks to the words beyond the match, we can score all these candidates so that only the entity Berkeley Square (TV series) clearly wins. And that is correct.
The query east ridge high school should be linked with these four entities in the ERDC entity collection, but not with the Eastridge High School. And robert griffin hurt should result in the two entities only who play football, and not the others.
Semantic search tasks
Entity linking
Aka entity recognition and disambiguation. Return the particular entities found in the knowledge base that are referred to from within a given text. Possibly, rank the entities or provide some measure of association of the entity to the text. Entity linking can aim at the individual mentions of entities in the text, or can be applied to the text as a whole: for queries as well as documents.
Knowledge base acceleration
This task combines named entity recognition and information extraction. Suggest that a piece of text is a mention of an entity that is not yet in the knowledge base, and determine the type of the entity (e.g. date, location, person, organization). Discover new or conflicting information about the entities implied by the text, and represent it in the updated knowledge base.
Entity retrieval
Return a ranked list of entities relevant to the query. Display the information about the entities that is of interest and importance (cf. documents and snippets in information retrieval). Possibly, limit the number of returned entities in favour of more detailed information that gets displayed.
Question answering
Use techniques like semantic parsing and inference/reasoning on the knowledge base to provide answers to questions/queries in natural language. Consider the context of the questions.