The Seznam.cz website receives around 4 million visitors a day, mainly for infotainment. Although it may not seem obvious, this site is literally packed with new technologies, and Machine Learning (ML) / Artificial Intelligence (AI) technologies play the leading role among them.
If you tried to find information about ML on Seznam.cz, you would probably come across Seznam’s internet search engine, its excellent online services such as Mapy.com, Zboží.cz and Sreality.cz. No doubt you would also find the news about SeLLMa – Seznam’s own Large Language Model (LLM) that powers its online services.
In this article, however, we will focus on the Seznam services that are usually overlooked or seemingly less popular – the content recommendation and advertising systems. You may be very surprised at the powerful ML machine that hides under the hood of these services.
Content Recommendation
The content offered on Seznam.cz is selected by the recommendation service. There are dozens of ML models that provide this highly personalised service. An ML model is an intelligent algorithm that learns from data and is able to provide an optimal output for an input based on data collected in the past.
The tasks solved by the ML models as part of the recommendation service are calculating the optimal number, order and size of thematic sections, summarisation and thematic clustering of recommended articles, relevance-based selection and ranking of articles (there are tens of thousands of articles in the recommendation database), user identity and estimation of user profile (age, gender, interests), characterisation of articles and videos (quality, degree of clickbaitness, degree of local relevance, specificity, etc.). – each characteristic has its own ML model).
Below are a few selected examples of ML models used to make recommendations for a deeper insight:
Article retrieval
Task: From all the items in the database (item = article, podcast, video or any other form of content), select about a thousand that could be of interest to the current user. In real time (tens of milliseconds).
Solution: Retrieval is actually a super-fast search for the most similar items. It is necessary to pre-calculate vectors for items and store them in a special structure that allows fast access and search. Retrieval then calculates the similarity between the item vectors and the user’s vector, then searches for the most similar items – the algorithm works with sub-linear time complexity.
Article ranking
Task: Evaluate the relevance of retrieved items in real time. (So that they can be displayed in order of relevance for each user).
Solution: Relevance is calculated using the Deep and Cross Network (DCN) model based on complete item and user data. DCN captures non-trivial relationships between user data and item data. The model is trained on historical data and retrained on new data every 5 minutes.
Assessing the “localness” of articles
Task: Estimate the “localness” of articles, videos or other items in the database of items. (An item marked as local is relevant to a specific geographic location, such as a city or region, and therefore may be relevant to users interested in that location. Under such circumstances, the relevance of such items is enhanced and may be recommended to the user).
Solution: The localisation classification is performed by a small language model (built on the basis of the pre-trained retromae-small-cs model), which is trained with an emphasis on semantic embeddings using data generated by the LLM (SeLLMa 70B by Seznam.cz). This combination allows us to exploit the strengths of the LLM at the cost of a small language model.
No ML, no interest
Every day, hundreds of thousands of articles, podcasts, videos, photo galleries and other forms of content in Czech and other languages are processed by the Seznam.cz recommendation service. Without the power of ML, there would be no personalisation and there would be manually selected content displayed on Seznam.cz, the same for all users. Seznam.cz would lose its appeal for most users.
We have rigorously evaluated the huge contribution of the recommendation service in terms of the time users spend on our content network. It is certain that in the long term, non-existent or dysfunctional recommendation would result in the loss of the user base.
Online advertising
The Advertising System (AS) serves Seznam.cz customers – advertisers. However, it is very important to place the advertisements in such a way that they do not irritate the online users and, if possible, serve them. Like the recommendation service, AS uses the user’s identity, pre-calculates the user’s profile and the characteristics of the web pages displayed.
However, there are many differences between the two: the AS also needs to precompute the characteristics of advertisers and their ad campaigns, there are about an order of magnitude more ad rankings compared to recommendation rankings, and there is a hierarchical online auction set for each ad placement.
Conversion prediction
Task: Calculate in real time (less than 50 miliseconds) the probability of conversion of the ad to be displayed, assuming it would be clicked. The task of predicting conversion is extremely difficult due to the scarcity of conversion data (only 4 clicks out of a hundred result in a conversion), the wide variety of conversion types and amounts, and the possible long delay in conversion (conversion is taken into account even if it occurs 30 days after the click).
Solution: The logistic regression and Poisson regression models predict the occurrence of conversions and the number of conversions, respectively. The predictors are trained on several months of data and are automatically retrained with new data every day.
Bidding optimisation
Task: For each ad impression, determine an optimal value for the advertiser to bid so that their ad campaign receives the maximum number of conversions.
Solution: Feedback loop that controls bid pricing in each auction based on user, ad and ad context data, using the number of conversions received and the estimated number of conversions expected.
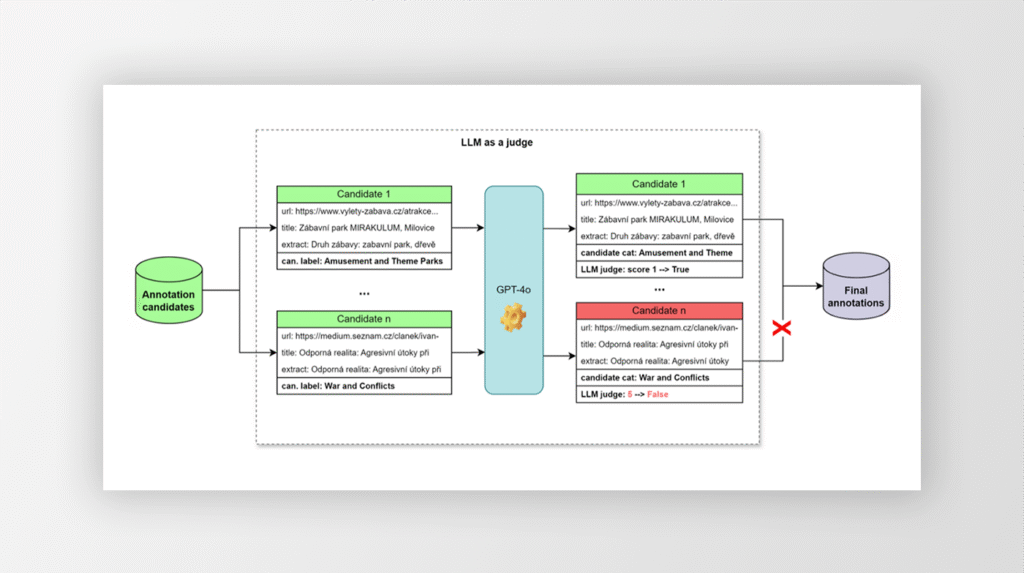
Online content classification
Task: For each web page among the hundreds of millions of pages in the Seznam content network, its interest category is determined. (High quality website rendering is required to display ads and article recommendations that are relevant and interesting to online users).
Solution: The pages are classified into the standard IAB content taxonomy using a sophisticated Bert based classifier. The classifier combines a pre-trained dist-mpnet model with a proprietary MLP layer optimised by regularisation and mix-up augmentation techniques. The preparation of high quality training data is fully automated.
First, potential candidates for each category are identified based on the similarity of the semantic vector representation of the texts. The candidates are then evaluated by an advanced LLM model using the LLM as a Judge (LLMaaJ) technique. This approach delivers consistently high quality online content classification, regardless of constantly changing content, and without the need for tedious manual data annotation.
Online advertising without ML?
Seznam AS handles tens to hundreds of thousands of requests per second. Advertising without ML would work, but it would work badly. Ads would either be identical for every online user, or randomly assigned without regard to individual interests. This would probably result in more ads per page to meet advertisers’ goals. So why not get rid of ads altogether? Unthinkable!
Online advertising actually funds all online content and all the fantastic online services and applications that users get mostly for free. It’s also thanks to online advertising that Seznam can maintain world-class R&D teams responsible for developing and implementing the ML technologies described above – including Seznam’s own LLM development mentioned above. And you may also be aware that Seznam invests in the wider ML community.
Working on ML tech in Seznam
Advertising and recommendation systems are among the most demanding systems to operate, maintain and improve due to their complexity and the size, velocity and variety of the large amounts of data they process. This means continuously solving many difficult challenges. On the other hand, it offers an exceptional opportunity for ML researchers and developers: the work provides unparalleled experience – if you can handle it, you can handle pretty much anything in the world.
What is the working day of ML researchers and developers like? The work is guided by agile methods. Each task is first given to the research teams. Researchers analyse the problem, review published state of the art (SOTA) solutions and propose a solution. They then develop and test the solution to the stage of a working prototype. The prototype, along with detailed documentation, is then handed over to the ML developers, who implement it in the production pipeline, ensuring that it meets all the demanding production-grade requirements (quality, speed, latency and HW constraints).
Each developer and researcher is equipped with top-of-the-range tools and given ample time for professional development. Great attention is paid to systematic training and self-improvement, including individual and team reading of technical literature, attending internal and external training courses, attending international conferences and even publishing there.
If you found this article interesting, and would you like to explore a career at Seznam, here is your opportunity – just check out this job post and apply. If you are interested in other ML related positions at Seznam, feel free to browse our career page.
Fun and creative work with many interesting challenges and real impact on Seznam’s end users, combined with an informal and pleasant working environment and unique opportunities for professional growth – all this explains why new researchers and developers apply for ML positions at Seznam and why they like to stay.
Vít Líbal, Research Department of Advertising Systems
Seznam.cz grew by 6% year on year in 2012. The company’s revenues from advertising amounted to CZK 2.834 bn. Seznam.cz’s 2012 operating profit reached nearly one billion. Seznam.cz carries on in product and technological innovations. Its plans include enhanced possibilities of targeted advertising and the development of its own data centre.
Seznam.cz continues to support StartupYard, the Prague based accelerator, for the third year running and has decided to further deepen its co-operation with StartupYard.