In the previous blog post, we have pointed out that the modern Recommendation Systems became widespread as they significantly improve user experience of consumers of online services and goods. For the same reason, the RS became subject of advanced research in leading technological companies. In this blog post, we will closely look at how the RS work and what is making them so successful in delivering the online users great experience.
Before we jump into the details of the topic, we wish to mention an event that may be very relevant for anybody who wishes to learn more about the RS and about the science behind the RS: In May, company Seznam.cz will organize the workshop “Recommendation Systems and User Representations” at the scientific conference ML Prague 2022. The workshop participants will be presented the state of the art of the Recommendation Systems research including the deep neural net (DNN) architectures using the RS. Also, a part of the workshop, a tutorial of the RS will be given during which the participants will be able to train a DNN based recommendation model and evaluate benefits of various DNN architectures and user representations. The presentation and the tutorial will be focused on solving practical problems appearing in the RS especially the cold start problem.
So how do the RS work?
If an online service employs a RS, the RS starts acting at the very moment when the user starts using an online service, but still before she starts selecting a particular item from all items available to her through the service – for example, in case of a user of an online news portal, the RS delivers reader’s customized news selection exactly between the moment when the reader opens a portal page and the moment when the content of that “landing page” is displayed to her. At exactly that time, the online service sends the RS a request, typically in the form of a search query or in the form of a HTTP request to display the content. If we stay with the example of the reader of the online news portal, the landing page may contain a news article previously selected by the reader and the RS would generate – based on the information about the page and based on the information previously collected about the reader – a list of clickable links that the reader is likely to read next. That list of clickable links would then typically be inserted into dynamically generated content of the landing page, e.g. into the area under the article text.
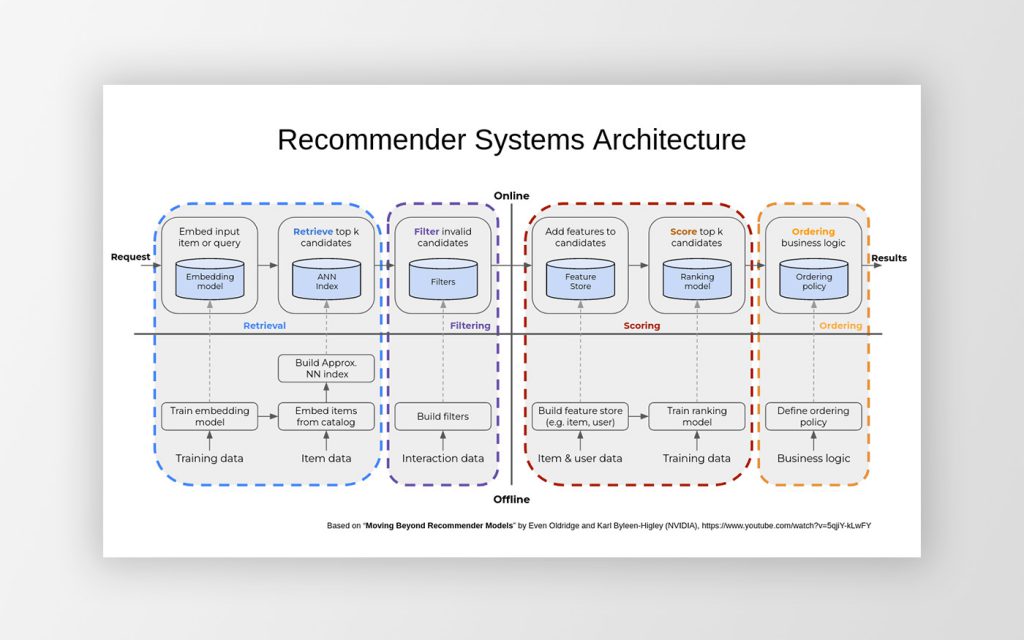
There are four main tasks that a typical RS performs to form an output list of recommendations out of the initial request: retrieval, filtering, scoring and ordering.
The retrieval takes a subset of information contained within the input request and uses it to rapidly narrow the set of all options to a much smaller set of those options that have any chance to be selected by the user. There may be tens of thousands, perhaps millions of items in the database of the online service and it would be unfeasible for the RS to score all of them for each user. This rapid pre-selection is motivated by the speed requirements. As the user expects to receive nothing but a smooth service, the RS must deliver its output recommendations within a few tens of milliseconds from receiving the request. Resulting list of pre-selected items may contain hundreds, perhaps thousands items – a number that already allows the RS to score all pre-selected items separately in time.
The filtering applies a set of rules to the list of pre-selected items created in the retrieval stage so that those items are dropped that serve no further purpose (e.g. skipping articles already read by the user). It makes no sense to use ML methods and to construct sophisticated ML models for this purpose – employing a straightforward filter will achieve better results with fewer resources.
The scoring employs a ML model trained, using the historical data (collected during the past interaction of users with the RS system), to assign a score to each item on the filtered list of items. This score should measure the user’s interest in each item, in other words, it should reflect the user’s personal preference when she is selecting from among the items. At this stage, we prefer an accuracy of the score over the time that it takes, thus all relevant information from the input query and all available information on the user are taken into account. An example of a ML model that performs the scoring may be a deep neural net that – upon presenting it the item data coming from the input request – produces click prediction for the item together with its clickthrough probability. The clickthrough probability then becomes the output score of the item.
The ordering takes into account the item’s score and uses it to sort the items before the list of items is handed over to the RS output. Also at this stage, the output list of items is truncated to the desired number of items according to the service’s business logic requirements. In our example of the news portal, five to ten top scored articles may be selected and offered to the user.
As it may be apparent to the reader, the key elements of RS are the ML models at the core of the retrieval stage and the ML models performing the ranking in the scoring stage. It is the quality and the efficiency of these ML models that determines the success of resulting recommendations and consequently the user’s satisfaction with the service. Sophisticated ML methods such as linear models, collaborative filtering and deep neural nets are employed in the modern RS. These methods are subject of intensive research and continuous improvement.
If you are further interested in the technologies behind the recommendation systems or if you wish to get a deeper understanding of the scientific research of the recommendation systems, we would like to cordially invite you to visit our workshop “Recommendation Systems and User Representations” at the scientific conference ML Prague 2022.
In May this year, Seznam.cz will organize a workshop in English language called “Recommendation Systems and User Representations” at the scientific conference Machine Learning Prague 2022. Participants will learn about the current state of research on recommendation systems, including the deep neural network architectures used in them. The workshop will include a practical part, during …