Technologie fulltextu
Přehled
Následující text uvádí stručný popis procesů, které proběhnou potom, co zadáte dotaz do vyhledávacího pole.
Fráze je nejprve zpracována webovým rozhraním a rozšiřovačem dotazu (Query Processor) – to znamená, že se provede kontrola pravopisu, případně se doplní diakritika atd. Výsledná fráze (dotaz) je zaslána do agregátorů hledání (Search Aggregator). Server indexu vyhledá dokumenty v indexu a vrátí nejrelevantnější výsledky agregátoru hledání. Ten vybere 10 nejvíc relevantních výsledků a zašle požadavek Snippet Serveru, který ke každému z nich přidá titulek webové stránky a úryvek. Tyto výsledky jsou pak vráceny jako výsledek na váš dotaz. Všechny tyto procesy se dějí online.
Data jsou stahována z Internetu robotem (web crawler) a poté jsou uložena do databáze dokumentů. Z té jsou pak dokumenty postupně vybírány na indexaci a uložení v Indexu. Obnovování databáze dokumentů probíhá pravidelně (týdně, denně a každých několik minut).
Následující diagram ukazuje tok dat: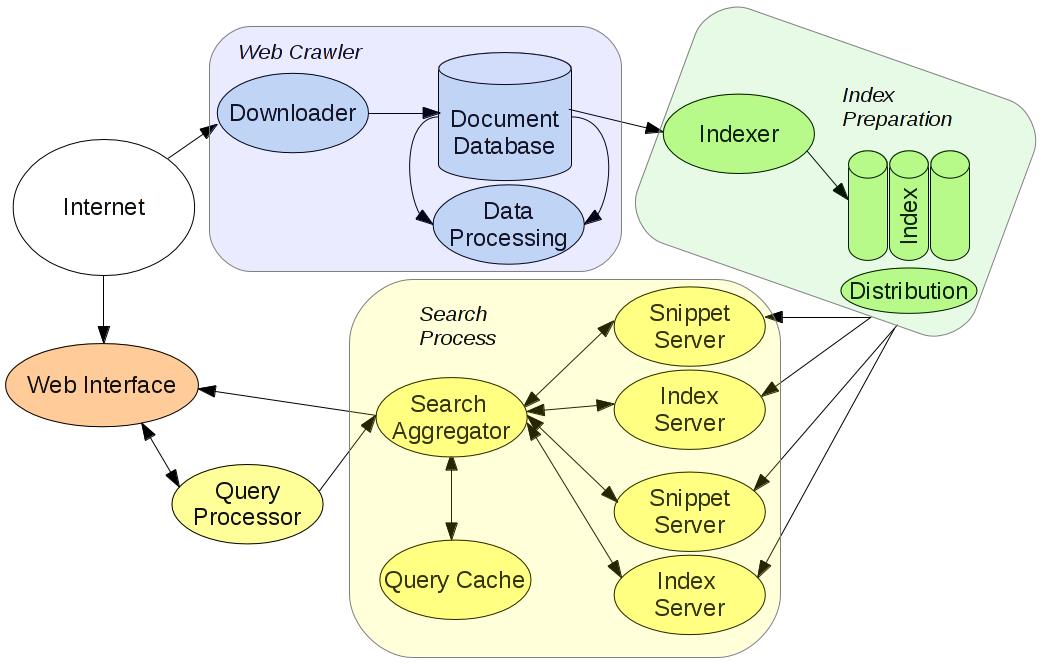
Následující sekce podávají podrobnější popis všech komponent.
1. Query Processor
Query Processor zpracovává frázi, kterou jste zadali. Proběhne kontrola pravopisu, jsou rozvinuty zkratky a doplní se případná synonyma a diakritika. Vznikne tak rozšířený dotaz, který je poslán Search Aggregatoru. Tato implementace umožňuje získat širší rozsah relevantních výsledků a také vrátit relevantní výsledky i v případě, že fráze byla zadána nesprávně.
Query Processor používá sadu procesů aby upravil zadanou frázi následovným způsobem:
- hledá dvojslovná spojení
- určí tematiku fráze
- vykoná rozšíření zkratek nebo vytvoří zkratky
- rozdělí nebo vytvoří složená slova
- zjistí, jestli člověk zadal přesnou frázi
- vytvoří související slova
- vytvoří alternativní zápis čísel nebo zkratek
- identifikuje slova v hledané frázi, která můžou být vynechána z hledacího procesu
- hledá čárku a rozdělí hledanou frázi
- hledá strukturu doménového jména v hledané frázi
- převede čísla na jejich tokenovou reprezentaci anebo na text
- převede ligatury na běžné znaky
- spojí tokeny oddělené znakem + nebo &
2. Search Aggregator
Search Aggregator dostane dotaz z Query Processoru a pošle ho Query Cache pro ověření, jestli se podobný dotaz nezpracoval již dříve.
Query Cache ukládá poslední relevantní výsledek připravený na zobrazení uživateli. Tyto uložené výsledky obsahují také úryvky (snippety).
Pokud Query Cache neobsahuje vhodné výsledky, dotaz je zaslán Index Serveru. Po zpracování dotazu Index Serverem je 10 nejrelevantnějších výsledků vrácených Search Aggregatoru.
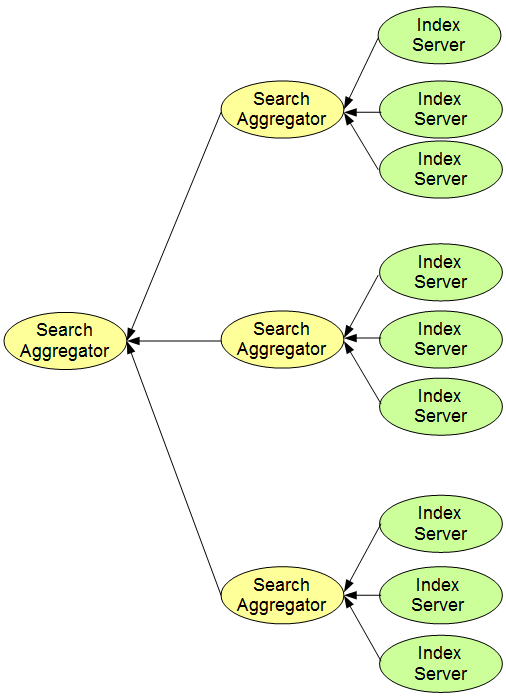
Agregátory hledání mají stromovou strukturu. Každý agregátor dostane výsledky z několika serverů indexu a vybere 10 nejlepších výsledků. Jiný agregátor hledání je připojen k těmto agregátorům a provede výběr 10 nejvhodnějších výsledků z agregátorů hledání – viz obrázek nahoře.
Poslední agregátor hledání ve stromu pošle požadavek Snippet Serveru pro úryvky. 10 výsledků je potom přímo posláno webovému rozhraní.
3. Index Server
Index Server vykonává hledání v databázích indexu. V provozu je vždy vícero (přibližně 200) serverů indexu. Každý server indexu vykonává hledání v odlišné indexové databázi. Taková implementace vede k odlišným výsledkům z odlišných serverů indexu.
Jestliže hledaná fráze obsahuje více než jedno slovo, výsledek je průnikem. Server indexu určí, jestli je výsledek relevantní na hledanou frázi, např. pokud hledaná fráze je „bílá kočka“, nejenom nalezené dokumenty musí obsahovat obě slova „bílá“ a „kočka“, ale navíc také musí tato slova být v dokumentu blízko u sebe.
4. Snippet Server
Snippet Server přidá všechny informace o dokumentu – url, titulek stránky, obsah, odkazy atd. k 10 výsledkům. Také vytvoří úryvky(snippety) – dynamické popisky a texty které obsahují zvýrazněné části textu odpovídající dotazu.
I v případě, že je počet snippet serverů a serverů indexu stejný, snippet servery se použijí pouze na tom serverovém stroji, kde servery indexu najdou relevantní výsledky. Tato implementace snižuje síťový provoz na serverových strojích, protože snippet server se používá zřídka (snippet server v porovnání se servery indexu pracuje s velkým objemem dat).
5. Index
Clusterová databáze indexu ukládá indexované dokumenty. Současná implementace obsahuje následující části:
- word barrel – ukládá seznam dokumentů pro každé známé slovo a také ukládá počet výskytů (hitů) daného slova v dokumentech
- document barrel – ukládá seznam všech dokumentů ve svazku
- title barrel – ukládá obsah zpracovaných webových stránek a metadata
- query site barrel – ukládá informaci o tom, kolik unikátních dotazů zpracovaných z jednoho webu obsahovalo specifické slovo
- site barrel – ukládá seznam dokumentů pro weby
- link barrel – ukládá hypertextové odkazy ukazující na webové stránky
- qds barrel – ukládá hodnoty signálů pro rank zpětné vazby pro specifický dotaz
- queryurl barrel – ukládá informaci o tom, které unikátní dotazy vedou na stejnou URL
6. Indexer-worker
Hlavním účelem indexer-workeru je připravit dokumenty z databáze dokumentů na uložení v indexu.
Indexer-worker vykonává na dokumentech následující operace:
- zjistí, jestli dokument je ve formátu HTML
- určí jazyk dokumentu
- zkontroluje, jestli stránka není spam
Indexer-worker rozdělí dokument na jednotlivá slova a vykoná inverzní indexaci – každé slovo dostane seznam dokumentů, kde se nachází.
7. Robot (web crawler)
Robot a jeho část fresh robot jsou komponenty, které pravidelně stahují webové stránky (dokumenty) a provádějí jejich analýzu. Zatímco robot stahuje stránky denně, fresh robot je navržen tak, aby stahoval rychle se měnící stránky (např. zpravodajské články) v krátkých časových odstupech.
Robot se skládá z těchto částí:
- Databáze dokumentů – clusterová databáze, která ukládá všechny dokumenty spolu obsahem dokumentů, ranky, spočtenými statistikami, zpětnými odkazy atd.
- Hkeeper – je klíčovou částí robota, jelikož je odpovědný za plánování všeho stahování, určuje ve kterých stavech dokumenty jsou, spravuje mazání a vytváření dokumentů a připravuje dokumenty na stažení pro fresh robota.
- LinkRevert – je složka, která provádí analýzu zpětných odkazů – určuje jazyk a tematiku zpětných odkazů, které můžou pomoct určit jazyk anebo tematiku cílového dokumentu i když dokument ještě nebyl stažen.
- Indexfeeder – vybírá dokumenty na indexaci, jelikož pouze některé dokumenty mají takovou kvalitu, aby se dostali do vyhledávacího procesu. Indexfeeder rozděluje vybrané dokumenty do složek dále používaných indexer-workerem.
- Downloadery – pravidelně prochází Internet a stahují webové stránky.
- Manažer downloaderů – spravuje downloadery.
Fresh robot je „zjednodušená“ verze webového robota s jemně odlišnými komponentami:
- LinkFeeder – používá se k parsování stažených RSS a HTML souborů
- Fresh databáze – ukládá data potřebná pro plánování feedů.
Downloadery a manažer downloaderů jsou stejné, ale nepoužívá se Hkeeper – fresh robot používá denně exportována data z databáze.