Dnešní díl seriálu o sémantické analýze textů je zaměřen na problematiku snížení počtu dimenzí vektorových prostorů určených pro reprezentaci textových dokumentů.
V předchozím dílu seriálu, vysoký počet dimenzí může představovat velký problém. Vzhledem k tomu, že jsme doposud pracovali s prostory, kde každá dimenze reprezentovala jedno slovo jazyka, je zřejmé, že máme co dělat s dimenzemi o velikosti v řádu statisíců, což už je opravdu hodně.
Ke snížení počtu dimenzí v podstatě existují dva přístupy. Prvním z nich je tzv. výběr příznaků (feature selection), což jsou postupy, pomocí kterých jsou z původní množiny příznaků (složek vektorů) vybrány pouze ty příznaky, které jsou nějakým způsobem nejvýznamnější. Vybrané příznaky ale zůstanou nezměněny. Druhým přístupem je extrakce příznaků (feature extraction). V tomto případě dojde k nahrazení původních příznaků novými, jejichž počet je však nižší.
Nejprve se zaměřme na jednodušší metody redukce dimenzionality, které jsou založené na výběru příznaků. Jak už bylo napsáno v předchozích dílech, dokumenty máme reprezentované velice dlouhými vektory, které obsahují téměř samé nuly. Pouze u dimenzí reprezentujících slova, která jsou v daném dokumentu obsažena, může být místo nuly libovolné reálné číslo. Otázkou tedy je, jestli bychom nemohli zanedbat dimenze, které jsou téměř u všech dokumentů nulové. Jinými slovy, můžeme si dovolit ignorovat slova, která se vyskytují jen v několika málo dokumentech a vyplatí se nám to?
Nejprve zkusme zodpovědět otázku, zda si to můžeme dovolit. Jsou aplikace, kdy to udělat nemůžeme. Např. u fulltextového hledání to dělat nejde. Asi bychom neudělali radost člověku s unikátním jménem, které se vyskytuje pouze na jeho domovské stránce, tím, že by v našem vyhledávači nebyl dohledatelný. Jistě však najdeme aplikace, kde si to dovolit můžeme. Příkladem může být detekce duplicitních dokumentů. Ať už je řešena jakýmkoliv způsobem, zanedbání slov s minimální frekvencí nám zřejmě vadit nebude.
Druhou otázkou je, jestli se nám to vyplatí. Pro nalezení odpovědi se podívejme na frekvenční analýzu slov. Ve všech přirozených jazycích platí tzv. Zipfův zákon. Ten říká, že pokud všechna slova z nějaké kolekce textů seřadíme sestupně podle frekvence a očíslujeme je od jedné, potom součin tohoto pořadí a frekvence slova zůstává pro všechna slova přibližně konstantní. Jinak řečeno, pokud má nejčastější slovo frekvenci 1000, druhé nejčastější má frekvenci 500, třetí 333 a tak dále. S výjimkou těch nejméně a nejvíce četných slov toto pravidlo funguje velmi dobře. Graf závislosti pořadí a frekvence ze vzorku námi indexovaných dokumentů je zobrazen níže (obě osy jsou logaritmované):
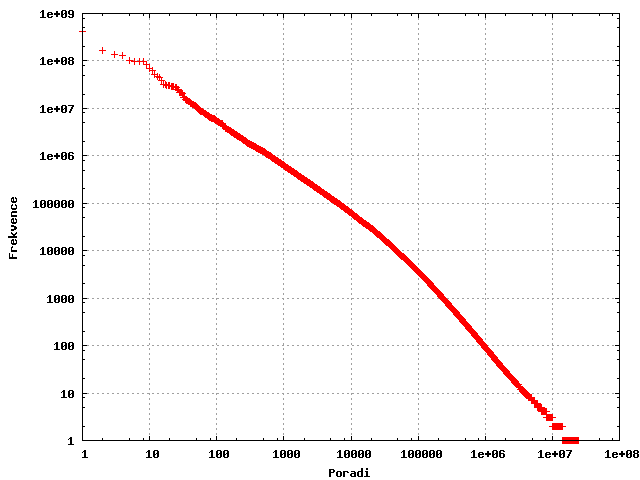
Jedním z nejdůležitějších důsledků Zipfova zákona je fakt, že základ jazyka je tvořen relativně malým počtem stále se opakujících slov. V naší kolekci textů se více než polovina slov vyskytuje pouze jednou. Kdybychom si mohli dovolit ignorovat všechna slova s frekvencí < 10 (v naprosté většině se jedná o překlepy a chyby), snížíme počet slov dokonce na 17 %. Zcela určitě se tedy takový způsob redukce dimenzionality vyplatí. Na problematiku se lze dívat i z druhé strany a vytvořit seznam takzvaných stop slov, která se vyskytují velice často, ale nenesou žádný význam. Jedná se převážně o spojky a předložky. Vypuštěním takových slov se však počet dimenzí příliš nesníží a jedná se spíše o optimalizaci pro rychlejší vyhledávání. Existuje celá řada dalších metod, které vybírají významná slova chytřeji, ale o těch třeba někdy jindy.
Druhým zmiňovaným způsobem snížení dimenzionality je extrakce příznaků. Jde tedy o nahrazení původní množiny příznaků nějakou novou. Jestliže původní množinou příznaků byla všechna slova, která se vyskytují v dokumentech, je nasnadě sloučit do jedné dimenze slova, která mají stejný význam. Jedním z nejjednodušších způsobů jak toho dosáhnout je tzv. lemmatizace nebo stemming. Lemmatizací rozumíme převod slova na jeho základní tvar, stemmingem převod slova na jeho kmen. Například základním tvarem slova učil je infinitiv učit a kmenem je uč. Stemming se běžně používá např. pro angličtinu, ale u vysoce flektivních jazyků, jakým je čeština, je výhodnější použít lemmatizaci. Jakmile známe u každého slova lemma, můžeme původní vektorový prostor slov nahradit vektorovým prostorem lemmat a všechna slova zobrazovat na dimenzi odpovídající jejich lemmatu.
Velkým problémem lemmatizace a stemmingu je víceznačnost. Např. slovo letech může mít dva významy a tudíž dvě lemmata – let a léto. Po nalezení všech možných lemmat je tedy většinou potřeba vybrat to správné, nejčastěji podle větného kontextu. Této fázi se říká desambiguace.
Víceznačnost však může být ještě záludnější. Např. slovo oko má celou řadu významů (zrakový orgán, smyčka, karetní hra atd.), ale lemmatem je stále oko. Kromě toho bychom rádi sloučili i slova, která mají stejný význam, ale nemají shodný základní tvar. Takovým párům slov se říká synonyma a příkladem mohou být dvojice zubař vs. stomatolog, zde vs. tady apod. Abychom se dokázali vypořádat i s tímto, je třeba přejít ke složitějším technikám extrakce příznaků. Jednou z nich je latentní sémantická analýza, se kterou se seznámíme v příštím dílu, a začneme tak konečně naplňovat název seriálu, který má být převážně o sémantice.


