Už pár let se v odborných periodicích, na IT serverech i různých blozích pravidelně objevují termíny cloud, big data, NoSQL databáze a všichni zasvěceně přikyvujeme. Člověk se sice moc nedočte, k čemu jsou dobré, ale jsou tu s námi a nechávají nás klidnými. Až do doby, kdy začneme řešit tu otázku, kam s nimi, s těmi velkými daty.
Pokud nejste úplně v obraze, ukažme si to nejdřív na nějakém příkladě. Představme si, že provozujeme velký zpravodajský server, máme k dispozici access logy pár let dozadu a dostaneme úkol zjistit čtenost jednotlivých rubrik a najít nejčtenější články. Logy jsou pochopitelně obrovské, gzipované, rozložené přes několik strojů, v horším případě zálohované na pásce. A potřebujeme to zjistit do zítra, protože to vedení potřebuje k dalšímu rozhodování nebo má zrovna vyjít PR článek, kde se tím máme pochlubit. Nemožné? Jistě, na jednom stroji by to šlo obtížně, na více strojích by to sice šlo, ale data budou chtít ručně zagregovat. Pro jednou to tedy nějak zbastlíme, ručně spojíme výsledky z jednotlivých strojů v tabulkovým kalkulátoru a při vhodné konstelaci hvězd se to třeba i stihne. Druhý den za námi přijde někdo z vedení, že by je zajímala statistika pro pracovní dny a víkendy zvlášť. Zatneme zuby a odpovíme: „Proč by ne?“….
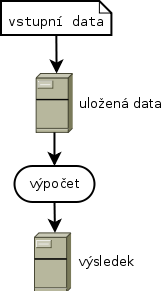
Většina z nás je nejspíš zvyklá takové výpočty provádět na jednom stroji a vystačí si s různými „standardizovanými“ nástroji jako je grep, sed, awk, nebo data nahraje do SQL databáze a dotazuje se přímo nad nimi. Jednoduchost je jasným přínosem a nelze ji popírat. Od určitého objemu dat a požadovaného množství výpočtů nutně narazíme a budeme nuceni změnit svůj přístup. Ve chvíli, kdy nám přestane pro výpočty stačit současný jeden stroj, můžeme koupit větší a lepší a data přesunout na něj. Časem to však může být příliš finančně nákladné nebo dokonce už takový stroj taky nemusí existovat. Můžeme si říct, že ty výpočty vlastně nepotřebujeme a data dál jen syslit. Není ale škoda mít k dispozici krásná data a nemít možnost s nimi pracovat?
Dobře, rozložíme data na více strojů a začneme řešit různé související problémy:
- kam a jak uložit vstupní data?
- jak spustit na všech strojích stejný výpočet?
- jak mezi více stroji přenášet mezivýsledky?
- jak spojit a kam uložit výsledky?
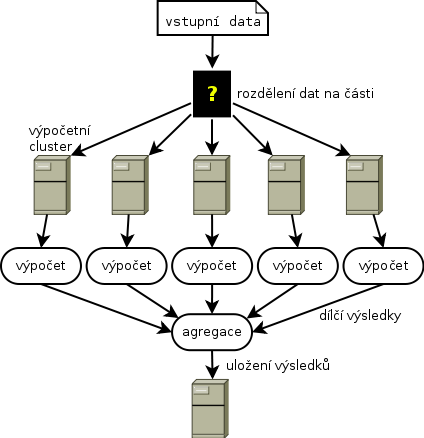
Naštěstí nejsme první, kdo si podobné otázky položil a tak už takové systémy existují. A přejdeme tedy rovnou k tomu z nejpopulárnějších a ještě k tomu zdarma – Hadoop. Tohle heslo za sebou dnes už skrývá pořádnou kupu firem a dalších projektů s ním spojených, nutno dodat, že situace není právě přehledná a než se ponoříte do hlubšího studia, doporučuji se pořádně nadechnout. Hadoop ekosystém je už teď tak velký, že v podstatě není v silách jednoho člověka pochopit a naučit se správně používat všechny v něm dostupné nástroje, zvlášť když vývoj probíhá tak překotně. Nechci Vás však odradit, naučit se alespoň část používat opravdu stojí za to, jen je nutné si na začátku dle popisů či zkušeností dalších lidí zvolit ty správné nástroje.
Vraťme se tedy k řešení námi položených otázek:
- data bude zřejmě nejlepší uložit do distribuovaného souborového systému, co třeba HDFS (Hadoop Distributed File System)?
- na všech strojích spustíme výpočet jako tzv. Map
- spojení mezivýsledků provedeme pomocí Reduce… a máme tu Hadoop MapReduce, ten pochopitelně zajistí i přenos mezivýsledků mezi stroji
- výsledky by se nám nemusely vejít na jeden stroj, takže je uložíme opět do HDFS
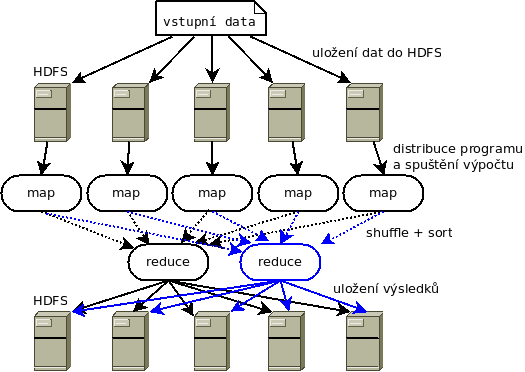
Prima, to bychom měli, vynalezli jsme základní stavební kameny Hadoopu a už víme, k čemu jsou dobré. Prozatím můžeme prohlásit vše ostatní za třešničky na dortu, které nám zpříjemňují či jinak zjednodušují práci s Hadoopem.
Hadoop je tedy framework pro distribuované zpracování velkých dat pomocí jednoduchého programovacího modelu. Celý systém velmi dobře škáluje, pokud chcete počítat s většími daty či výpočet urychlit, v podstatě stačí přidat do svazku další stroje. Základní myšlenkou je nespoléhat na spolehlivost použitého HW, ale zajistit vysokou dostupnost softwarově, tj. je možné použít levnější, ne příliš spolehlivé stroje, systém v případě selhání stroje tento odstaví a svazek pokračuje dál.
Je třeba zmínit, že základ Hadoopu je napsán v Javě, což s sebou nese určitá pozitiva i negativa tohoto jazyka. Vývoj jde rychle od ruky, na druhou stranu si člověk užije perné chvilky s použitou pamětí a garbage collectorem, zvláště v případech, kdy dopředu přesně nevíme, jak zpracovávaná data přesně vypadají, což je v případě dat získaných z internetu a z chování uživatelů častý jev. Pro psaní úloh je možné použít i jiné jazyky jako např. Python nebo C++, ale jsou zde určitá omezení a ve většině případů bude kód v Javě rychlejší nebo Vám nabídne více možností řešení určitého problému.
K čemu se Hadoop hodí:
- různé statistiky a histogramy z logů
- strojové učení
- analýza webových stránek
- vytvoření invertovaného indexu pro vyhledávání
- výroba jazykových korpusů
Příště se s Hadoopem seznámíme podrobněji.

