V minulém díle jsme si Hadoop představili a nyní se podíváme víc pod kapotu.
Prakticky o všem v Hadoopu se dá říct, že to není žádný převratný vynález nebo něco naprosto nepochopitelného. Vše je logickým vyústěním potřeby ukládat velká data a nad nimi provádět distribuované výpočty.
Z toho můžeme odvodit i základ Hadoopu:
- HDFS – distribuovaný souborový systém
- Map/Reduce framework – distribuované výpočty
To samotné by však pro každého nebylo dostačující, a tak nad Hadoopem je dnes už
postavena kupa dalších aplikací, která buď zjednoduše práci s ním, daty v něm
uloženými nebo poskytuje úplně nové funkce. Je možné, že Vás Hadoop zatím příliš nezaujal, je šance, že tyto další aplikace by mohly. Vyjmenujme tedy aspoň některé:
- Hive – datový sklad, který umožňuje nad uloženými daty spouštět HQL dotazy (podobné SQL)
- Mahout – knihovna pro strojové učení a data mining
- Pig – jazyk pro práci s uloženými daty bez nutnosti psaní Map/Reduce jobů
- Cascading – jazyk pro práci s uloženými daty bez nutnosti psaní Map/Reduce jobů
- HBase – NoSQL databáze
V tomto článku se podíváme podrobněji na souborový systém.
HDFS
HDFS je distribuovaný souborový systém napsaný v Javě (nechytejte se za hlavu,
je to rychlé) přímo pro potřeby spouštění Map/Reduce aplikací, určený k nasazení
na levném HW. Z toho plynou určité požadavky a omezení tohoto filesystému v
rámci co nejjednodušší implementace:
- odolnost proti chybám HW – můžeme se stavět na hlavu, ale počítače stejně
budou padat, přehřívat se, bude jim docházet paměť či místo na disku, disky
budou odcházet do křemíkového nebe či pekla a čím víc strojů ve svazku budeme
mít, tím větší bude pravděpodobnost, že k tomu dojde. HDFS je proto chytře
replikované, umí detekovat různé chyby a zotavit se z nich
- streamování souborů – důraz je kladen především na propustnost a ne na
přístupové doby
- orientace na velké soubory – velká data jsou uložená v rozumném množství
velkých souborů a ne v kupě maličkých
- co se jednou zapíše, už nelze změnit – aneb write-once-read-many, tj. jednou
zapsaný soubor už není možné měnit ani přidávat data na jeho konec (určitá
podpora pro append už sice existuje – HDFS-265, ale není to zdaleka tak jednoduché jako v normálním souborovém systému a používá se
jen ve speciálních případech)
- „Moving Computation is Cheaper than Moving Data“ – výpočet je efektivnější
spustit přímo u dat a ne tahat data po síti
HDFS si představte jako klasický souborový systém s adresáři, soubory a
oprávněními. Se soubory je možné provádět tradiční operace s výjimkou změny
souboru. Zajímavostí je trochu nezvyklý atribut souboru, a to počet požadovaných
replik. Soubory se dělí na bloky, velikost jednoho bloku je standardně 64MB.
hadice:~# hadoop fs -ls /user/michel
Found 2 items
-rw-r--r-- 2 michel grp 193 2011-12-29 14:54 /user/michel/fi10
drwxr-xr-x - michel grp 0 2011-12-29 15:20 /user/michel/fi10.wcl
Architektura
Architektura systému je tvořena především dvěma komponentami typu master/slave,
kde NameNode je master starající se o metadata – v podstatě seznam souborů a
adresářů, jejich mapování na bloky a umístění daných bloků. DataNode je slave,
který neví vůbec nic o souborech, slouží jako úložiště bloků, ty je na něj možné
zapisovat a pochopitelně z něj zase číst. DataNode reportuje NameNodu seznam
svých bloků a NameNode mu může nařídit blok někam dodatečně zreplikovat či smazat.
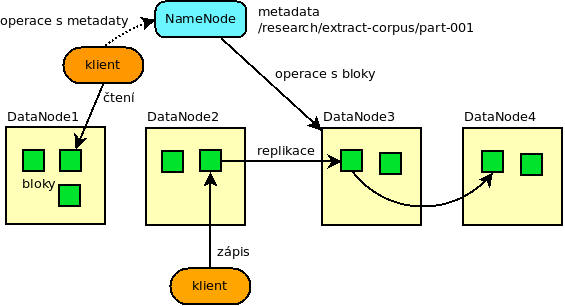
Klient může provádět operace se souborovým systémem, v tom případě se o vše
postará NameNode. Při čtení souboru si klient nejdříve na NameNode zjistí umístění
bloků daného souboru a pak již přímo komunikuje s patřičným DataNode. Data tak
proudí po síti přímo bez prostředníka. Zápis probíhá analogicky, klient nejdříve
založí soubor pomocí NameNode a ten mu řekne, jaký DataNode má použít.
Replikace
A jak je to s tou replikací? Data jsou replikována tak, aby na jednom stroji
ležela vždy jedna replika, tedy při stupni replikace 2 leží blok na 2 různých
strojích. Systém tak není odolný pouze před výpadkem jednoho disku jako u
diskových polí, ale je odolný před výpadkem celého stroje. Je na místě
zdůraznit, že v tom případě není nutné disková pole používat, ono je to totiž
dokonce nevhodné! Zajímavý je ještě samotný průběh replikace, při zápisu nového
bloku s replikací 3 klient provádí zápis pouze jednou, DataNody replikují data
ihned pomocí „replikačního vláčku“, první DN pošle data na druhý a druhý pak dál
na třetí.
Jak je vidět návrh HDFS není nějak zvlášť složitý, bylo by samozřejmě možné se
pustit ještě mnohem víc do hloubky, ale pro základní představu by nám to mělo
stačit. A jak to u nás používáme? Máme ve svazku 76 strojů s celkovou kapacitou
510 TB, což při replikaci 3 dává zhruba 170 TB, aktuálně máme asi poloviční
zaplnění a 9 miliónů souborů. Příště se podíváme na samotný Map/Reduce.

