Rok 2012 je za námi a s přechodem na nový rok přišlo i hodnocení toho předešlého. Média byla plná ohlédnutí za politickými a společenskými událostmi, ale doposud jsem v českém prostředí nezaznamenal žádnou retrospektivu z oblasti umělé inteligence a strojového učení. Přitom je toho tolik nového! Bezesporu jedním z nejdiskutovanějších témat umělé inteligence roku 2012 byla prudce se rozvíjející oblast nazvaná Deep Learning. Mnozí už o tomto fenoménu, který v soutěžích poráží ostatní metody strojového učení, slyšeli, ale stále je spousta lidí, kteří netuší, co se za tímto tajuplným názvem skrývá. Přestože je matematický popis bez znalosti širšího kontextu poněkud komplikovaný, základní myšlenka je jednoduchá a přímočará. Cílem tohoto článku je poskytnout čtenáři základní vhled do problematiky a zájemce odkázat na další zdroje.
Umělá inteligence je oblast lidského snažení, která se začala rozvíjet v podstatě od vzniku prvních počítačů. Pro pochopení Deep Learningu (omlouvám se za poněkud kostrbaté používání anglického pojmenování, ale zažitý český ekvivalent zatím neexistuje) je třeba se vrátit do padesátých let 20. století, kdy vznikly první umělé neuronové sítě.
Historie umělých neuronových sítí
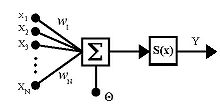
Jedním z přímočarých přístupů k řešení problémů umělé inteligence je snaha o napodobení fungování mozku. Mozek je podle dosavadních poznatků v zásadě síť vzájemně propojených neuronů, které si mezi sebou předávají signály pomocí elektrických impulsů a ty nějakým způsobem transformují. Každý neuron může mít libovolný počet vstupů, ale vždy jen jeden výstup. Schéma umělého neuronu je znázorněno na následujícím obrázku:
Neuron má vstupy x1, x2,…,xN, které jsou váženě sečteny s vahami w1, w2,…,wN a je k nim přičtena konstanta, tzv. bias Θ, někdy také označovaná symbolem +1. Výsledná hodnota je transformována nějakou funkcí S. Formálně tedy
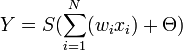 Výsledná hodnota může být vstupem pro jiný neuron nebo může být jednou z výstupních hodnot celé sítě. Typickou úlohou pro použití umělé neuronové sítě je problém, kdy máme na vstupu N číselných hodnot a výstupem je predikce M hodnot. Učení spočívá v nalezení správných hodnot parametrů wi a Θ všech neuronů. Například máme na vstupu obrázky reprezentované bitmapou a cílem je naučit síť rozpoznat, co je na obrázku zobrazeno. Neuronovými sítěmi lze řešit i jiné typy úloh, ale v tomto článku se omezíme pouze na tuto nejjednodušší.
Výsledná hodnota může být vstupem pro jiný neuron nebo může být jednou z výstupních hodnot celé sítě. Typickou úlohou pro použití umělé neuronové sítě je problém, kdy máme na vstupu N číselných hodnot a výstupem je predikce M hodnot. Učení spočívá v nalezení správných hodnot parametrů wi a Θ všech neuronů. Například máme na vstupu obrázky reprezentované bitmapou a cílem je naučit síť rozpoznat, co je na obrázku zobrazeno. Neuronovými sítěmi lze řešit i jiné typy úloh, ale v tomto článku se omezíme pouze na tuto nejjednodušší.
O tom, jak pracují jednotlivé neurony v mozku máme v celku jasnou představu, co ale stále zůstává otevřenou otázkou je propojení neuronů do sítě a způsob jejich učení.
První neuronovou sítí, kterou spolu s trénovacím algoritmem vymyslel v roce 1957 Frank Rosenblatt byl perceptron. Jedná se o jednoduchou jednovrstvou síť, která sestává pouze z jediného neuronu. Perceptron má však velmi omezenou expresivitu, neboť je schopen rozlišit pouze lineárně separovatelné třídy. Jak v roce 1969 v knize Perceptrons ukázali Marvin Minsky a Seymour Papert, jednovrstvé perceptrony se nejsou schopny naučit ani triviální funkci jakou je XOR.
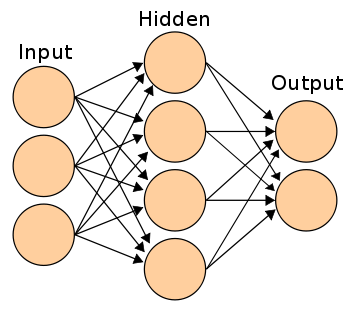
Zlom přišel v sedmdesátých letech, kdy byl objeven algoritmus zpětné propagace chyby pro trénování vícevrstvých neuronových sítí. Vícevrstvá perceptronová síť se skládá z několika vrstev perceptronů, které jsou navzájem propojeny. Každý perceptron následující vrstvy má za vstupy výstupy všech perceptronů předchozí vrstvy a tvoří tak úplný orientovaný bipartitní graf. První vrstva se nazývá vstupní, poslední vrstva výstupní a všechny ostatní skryté. Schéma vícevrstvé sítě je znázorněno na následujícím obrázku:
Algoritmus zpětné propagace chyby funguje tak, že se nejprve všechny váhy sítě inicializují náhodně, pro každý trénovací příklad se dopředných průchodem za použití stávajících vah spočítají výstupní hodnoty sítě a rozdíl hodnot oproti požadovanému výstupu se propaguje zpět do vstupní vrstvy. Současně se upravují váhy tak, aby se minimalizovala chyba. Tento postup dopředného a zpětného průchodu se opakuje do té doby, než je dosaženo nějaké minimální hodnoty chyby.
Vícevrstvé neuronové sítě už jsou schopny modelovat velmi složité nelineární závislosti a přesto, že může být algoritmus zpětné propagace v některých případech velmi pomalý, byly velmi populární až do poloviny 90. let. V roce 1995 však ruský matematik Vladimir Vapnik přišel s myšlenkou Support Vector Machines (SVM) , které se dají použít pro klasifikaci i regresi, jsou rychlé, na rozdíl od neuronových sítí stojí na pevném matematickém základu a především dosahují o poznání lepších výsledků. K SVM se postupně přidaly další velmi slibné přístupy (jako např. v poslední době velmi populární grafické modely) a praktický zájem o neuronové sítě začal opět postupně upadat.
Problém zpětné propagace
Skupiny zabývající se výzkumem neuronových sítí se naštěstí nenechaly neúspěchem odradit a zaměřily se na hledání příčin problémů u sítí s větším počtem vrstev (pět a více), které se zdály být slibné díky své schopnosti zachytit velmi složité závislosti.
Ukázalo se, že hlavním zdrojem problémů při trénování mnohavrstvých neuronových sítí je druhá fáze algoritmu zpětné propagace, při které se propagují chyby z výstupní vrstvy do vstupní. Tím, jak se postupnou eliminací rozdílů požadovaných a skutečných výstupů zmenšuje gradient chyby, ztrácí se informace o tom, jak modifikovat váhy. Nejvýznamnější podíl na vysvětlení problému na vstupu mají tedy vrstvy blízké výstupní vrstvě a nastavení hodnot vah vstupní a jí blízkých vrstev je z větší části určeno pouze náhodnou inicializací. Je tomu tedy opačně, než bychom očekávali.
Kámen úrazu je v tom, že existuje velké množství různých nastavení vstupních vrstev a pouze malá část z nich může pomoci vrstvám na vyšší úrovni. Je to o to horší, že optimální konfigurace jedné vrstvy závisí z velké části na té předchozí, při zpětné propagaci však informace o předchozích vrstvách není přímo k dispozici. Algoritmus tedy často skončí v nějakém lokálním minimu chyby, které má však často daleko k tomu globálnímu. Navíc, pokud se nepoužijí techniky jako např. regularizace, může kvůli nevhodnému nastavení vah dojít velmi snadno k přeučení sítě.
Vzhledem k tomu, že z těchto důvodů nemělo používání velkého množství vrstev smysl a pouze prodlužovalo čas trénování, bylo po dlouhou dobu doporučováno používat jednu nebo maximálně dvě skryté vrstvy. Výjimkou byly zejména případy, kdy bylo možné vstupní vrstvy snadno interpretovat a odborník na problematiku pak mohl přednastavit váhy ručně.
To se však v nedávné době změnilo.
Mnohavrstvé neuronové sítě a Deep Learning
Postupem času se ukázalo, že mnohavrstvé neuronové sítě nejsou v principu špatnou myšlenkou a mohou dokonce významně překonat jiné metody určené pro strojové učení. Důvodem dlouholeté skepse byla malá trénovací data a nedostatečná výpočetní síla tehdejších počítačů. Pokud máme k dispozici řádově větší data a výkonný cluster strojů se stovkami jader CPU nebo GPU, a necháme algoritmus zpětné propagace pracovat dostatečně dlouhou dobu, dospějeme k pozoruhodným výsledkům.
To je však i při dnešních výkonech počítačů nepraktické, proto bylo potřeba hledat jiné řešení. Tím kýženým řešením je předtrénování, spočívající v „chytrém“ nastavení počátečních vah. Konkrétně se jedná o dopředné natrénování parametrů všech vrstev neuronové sítě pouze na základě jejich vstupů. Jde tedy o metodu strojového učení bez učitele, která se nesnaží optimalizovat síť vzhledem k požadovaným výstupům, ale pouze jiným způsobem reprezentovat své vstupy.
Vstupní data velice často obsahují šum a redundanci, smyslem vyšší vrstvy je tedy odstranit nežádoucí šum a ze vstupních dat bez struktury extrahovat zajímavé vlastnosti. Další vrstva potom kombinuje výstupní atributy získané z předchozí vrstvy do obecnějších, a tak to pokračuje až k nejvyšší skryté vrstvě. Jakmile jsou předtrénovány všechny nižší vrstvy, je možné přidat výstupní vrstvu, která už pouze transformuje výstup poslední skryté vrstvy do požadovaných výstupů. V případě klasifikace do více tříd lze váhy této vrstvy např. určit algortimem softmax.
Bez informace o požadovaném výstupu při tvorbě nižších vrstev by však kvalita sítě nebyla příliš vysoká, proto tento algoritmus slouží pouze pro předtrénování parametrů a pro finální doučení vah se použije klasický algoritmus zpětné propagace. Předtrénováním je tedy nahrazena náhodná inicializace.
Tento postup lze pěkně zdůvodnit a ilustrovat na jednoduchém příkladu. Řekněme, že chceme natrénovat neuronovou síť, která má vstupem libovolnou bitmapu a cílem je rozpoznat, zda se na obrázku nachází konkrétní osoba (podobná síť by se např. mohla použít v bezpečnostních kamerách pro identifikaci podezřelých osob). Cílem první vrstvy by tedy mohla být například detekce hran v obrázku, abychom byli schopni identifikovat jednotlivé objekty. Další vrstva by pomocí hran identifikovala osoby, další by zachycovala jejich obecné vlastnosti, až bychom se dostali k nejjemnějším rysům obličeje a byli schopni osobu rozpoznat.
Takovýmto způsobem by nejspíš postupoval člověk, kdyby navrhoval vrstvy ručně. Cílem však je dokázat podobný postup provádět automaticky. A právě v tom spočívá princip Deep Learningu. V následujících odstavcích bude popsán jeden z nejjednodušších hladových přístupů založený na tzv. autoenkodérech.
Autoenkodéry
Autoenkodér je dvouvrstvá neuronová síť, ve které první vrstva kóduje vstupy sítě a druhá je dekóduje zpět ve snaze o co nejmenší chybu. Počet neuronů výstupní vrstvy je tedy totožný s počtem vstupů a cílem je produkovat na výstup stejná data jako na vstupu.
Na první pohled se může zdát, že je taková síť k ničemu, protože řeší identitu a může tedy prostě kopírovat vstup na výstup. Tak by tomu skutečně mohlo být, pokud by byl počet neuronů vstupní vrstvy alespoň takový, jako počet vstupních signálů. Zvolíme-li však počet neuronů vstupní vrstvy nižší, donutí to sít, aby se chovala úsporněji a snažila se o generalizaci.
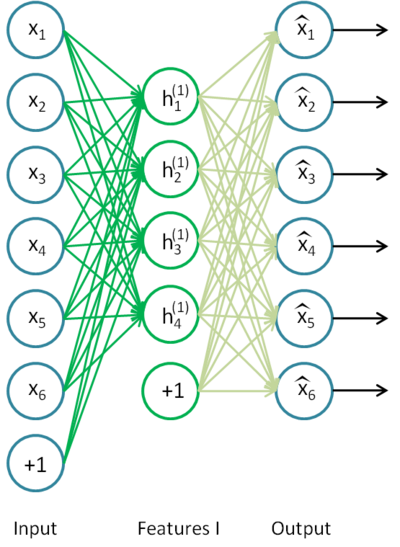
Výhodou autoenkodéru je, že má malý počet vrstev a není problém jej tedy natrénovat pomocí běžného algoritmu zpětné propagace s náhodnou inicializací. Schéma dvouvrstvého autoenkodéru je znázorněno na následujícím obrázku:
Použití autoenkodérů pro předtrénování mnohavrstvé neuronové sítě je přímočaré. Jakmile natrénujeme první vrstvu autoenkodéru (neurony h1, h2,…, h4 v obrázku), můžeme ji použít jako vstup jiného autoenkodéru a natrénovat další, obecnější. Takto lze postupovat až k výstupní vrstvě, která již řeší jednoduchý klasifikátor, a následně použít algoritmus zpětné propagace nad celou sítí pro její dotrénování. Výsledná síť složená ze dvou skrytých vrstev předtrénovaných autoenkodéry může vypadat podobně jako ta na obrázku níže:
Přístupů k předtrénování neuronových sítí existuje celá řada (Restricted Bolzmann Machines, Deep Kernel Machines, Deep Belief Networks, Deep Convolutional Networks, atd.) a stále vznikají nové a sofistikovanější. Úvod do těchto metod lze najít například v publikacích Learning Deep Architectures for AI nebo An Introduction to Deep Learning. Jejich popis však přesahuje rozsah toho článku.
Budoucnost strojového učení
S myšlenkou Deep Learningu přišel poprvé v roce 2006 Geoffrey E. Hinton se svým týmem. Od té doby se tato oblast strojového učení posunula o obrovský kus dopředu a byla publikována celá řada výsledků z oblasti zpracování obrazu, zvuku a přirozeného jazyka, kde tyto metody výrazně překonaly tehdejší state-of-the-art.
Rok 2012 se nesl ve znamení jejich popularizace i mezi laickou veřejností (např. titulní strana v The New York Times), kde vyvolala diskuse o tom, zda se blíží doba, kdy budou počítače schopny samostatného uvažování. Osobně se domnívám, že ke strojovému vykonávání takových činností jako je porozumění obrazové informace nebo řeči na úrovni člověka, natož ke strojovému uvažování, má lidstvo ještě hodně daleko, nicméně se jedná o další významný krok kupředu.
Zájemcům o danou problematiku můžu doporučit následují zdroje informací:
Jiří Materna