Entity ze Seznamu získaly dvě druhé ceny v soutěži ERDC 2014
Výzkumné oddělení Seznam.cz se zúčastnilo soutěže Entity Recognition and Disambiguation Challenge 2014, kterou organizovali Microsoft, Yahoo! a Google. Soutěžilo se ve dvou kategoriích a Seznam.cz získal druhou cenu v obou z nich. Propojování dotazů a částí dokumentů s entitami z Wikipedie nebo Freebase je důležitou součástí technologie sémantického vyhledávání.
Moderní internetové vyhledávače se snaží porozumět obsahu webových dokumentů, záměru uživatelských dotazů a kontextu, ve kterém se objevují. Aby toho v jistém smyslu mohly dosáhnout, využívají znalostních bází jako Wikipedia, Freebase, Linked Data a jiných zdrojů strukturovaných informací, ať už jsou otevřené, proprietární, všeobecné, či omezené na určitou oblast. Znalostní báze poskytují vhodný model našeho světa a entit v něm – lidí, míst, věcí, událostí, institucí, tvorů, substancí, pojmů, … co vás napadne.
- znalostní báze
- je konceptuální síť entit a vztahů mezi nimi
- entita
- je něco, co existuje samo o sobě, ve skutečnosti nebo pomyslně
- uri
- identifikuje model entity ve znalostní bázi
Cílem soutěže Entity Recognition and Disambiguation Challenge konané při konferenci ACM SIGIR 2014 bylo podnítit nové přístupy k problému propojení textů s entitami znalostních bází, tzv. úloze entity linking. Účastníci měli za úkol vyvinout systémy, které v daném textu rozpoznají zmínky o možných entitách, disambiguují je, tzn. odstraní ty, jež s uvážením kontextu nejsou relevantní, a ztotožní je s entitami v zadané množině entit nebo znalostní bázi.
Soutěž ERDC byla rozdělena do dvou kategorií: v první se hledaly entity v dotazech (Short Track), v druhé se hledaly entity v textech webových stránek (Long Track). My jsme se účastnili obou a nasadili jsme v nich ten samý systém, pouze doladěný pro tu kterou úlohu. Ve vyhodnocení jsme dosáhli úspěšnosti 71.9% na dokumentech a 66.9% na dotazech, čímž jsme se umístili na třetím místě a zároveň získali druhou cenu v obou kategoriích.
Níže bychom chtěli načrtnout rysy těchto úloh a zmínit řešení, která jsme pro ně vymysleli. Podrobnosti jsou k dispozici v našem článku. Zájemcům doporučujeme tento entity linking and retrieval tutorial, který nabízí důkladný úvod do celé problematiky.
Long Track: entity v dokumentech
V daném textu nalezněte zmínky relevantních entit a z každé zmínky odkažte na právě jednu entitu. Tento úkol je podobný rozhodování, kam umístit vysvětlující odkazy do Wikipedie, pokud byste editovali nějakou její stránku. Není ale stejný.

Obrázek napravo ukazuje příklad anotace (růžových) zmínek a (modrých) entit v daném textu, které by člověk očekával od automatického systému. Všimněte si, že obecná slova jako smartphone nebo manufacturer, jimž odpovídají stejnojmenné entity ve Wikipedii, by v tomto kontextu s entitami propojena být neměla.
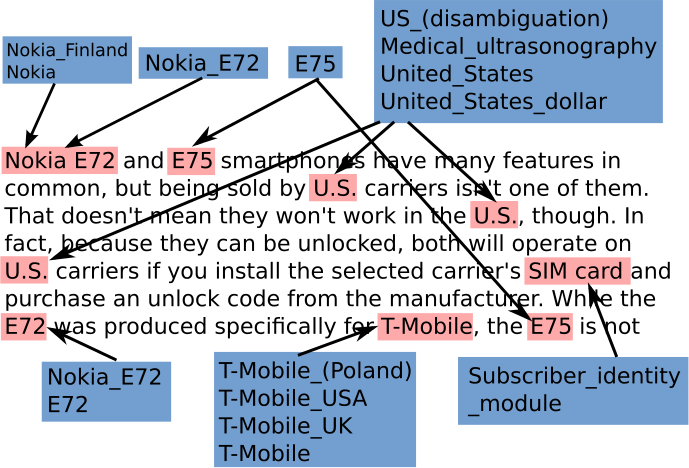
V druhém obrázku jsou vypsány entity, z nichž si náš systém musí jednoznačně vybrat poté, co určil jednotlivé zmínky a zkonfrontoval je se znalostní bází. Tyto kroky je třeba provádět s rozmyslem, neboť nechceme minout žádnou entitu, přitom ale velké množství nepřesně vytipovaných entit by zhoršilo výkonnost a zvýšilo výpočetní nároky celého systému. Zmínka E75 na očekávanou entitu nevede, nicméně zmínky E72, Nokia a Nokia E72 již zahrnují ty pravé kandidáty. Během disambiguace vypočítáme pro každou zvažovanou entitu její ohodnocení a pak pokračujeme pouze s těmi nejlepšími. Je třeba ošetřit sousední a překrývající se zmínky a dále zredukovat entity jen na ty, jež se vyskytují v množině entit zadané v rámci soutěže.
Nejnáročnější částí celé práce je patrně návrh hodnotící metody, protože vyžaduje tvůrčí přístup a zároveň odborný vhled. Náš systém má modulární architekturu umožňující snadné experimenty s různými nastaveními a metodami. Z řady možných kombinací jsme pro soutěž ERDC vybrali tu nejvhodnější. Jsme ale schopni svůj systém přizpůsobit tak, aby fungoval pro jiné jazyky a znalostní báze, a v prostředí našeho vlastního vyhledávače.
Klíčové body našeho přístupu k úloze propojení textů s entitami jsou: doplnění následných zmínek, odhad pravděpodobností zmínek a entit, sestrojení grafu souvýskytu entit a výpočet ranku a křivosti jeho vrcholů, a aplikace rozličných heuristik pro hledání a slučování zmínek a redukování entit.
Short Track: entity v dotazech
Pro daný dotaz vraťte množinu relevantních entit, které s ním souvisejí. Absence kontextu a zvláštní skladba dotazů dávají nahlédnout, proč toto zadání netrvá na nalezení zmínek a na jednoznačnosti řešení. Obě podúlohy je nutné do jisté míry provést, nevyhodnocují se však přímo.
Uvažme dotaz berkeley square mini series. Nasnadě je entita Berkeley, California. Existují ovšem dvě Berkeley Square v Anglii a další vytipované entity. Přesto, díky ostatním slovům v dotazu, dokážeme ohodnotit všechny tyto možnosti tak, že mezi nimi entita Berkeley Square (TV series) zřetelně vede. A tak je to správně.
Dotaz east ridge high school by měl být propojen s těmito čtyřmi entitami ze soutěžní množiny entit, ale nikoli s Eastridge High School. A robert griffin hurt by mělo odkazovat jen na ty dvě entity, které hrají fotbal, a na nikoho jiného.
Úlohy semantického vyhledávání
Propojení textů s entitami (entity linking) zvané též rozpoznávání a disambiguace entit (entity recognition and disambiguation)
Nalezněte takové entity ze znalostní báze, na něž je odkazováno z daného textu. Případně uspořádejte entity nebo je ohodnoťte podle jejich spojitosti s textem. Propojování textů s entitami může cílit na jednotlivé zmínky entit v textu, nebo může být aplikováno na text jako celek: pro dotazy i pro dokumenty.
Aktualizace znalostních bází (knowledge base acceleration)
Tato úloha kombinuje rozpoznávání jmenných entit (named entity recognition) a extrakci informací (information extraction). Upozorněte, že jistá část textu zmiňuje entitu, která ještě není ve znalostní bázi, a určete typ této entity (např. datum, místo, osoba, organizace). Objevte novou nebo protichůdnou informaci o entitách z textu a reprezentujte ji v aktualizované znalostní bázi.
Vyhledávání entit (entity retrieval)
Vraťte uspořádaný či ohodnocený seznam entit relevantních k dotazu. Zobrazte takovou informaci o entitách, která je důležitá a je předmětem zájmu (srov. dokumenty a jejich úryvky (snippety) ve vyhledávání informací (information retrieval)). Případně, rozhodněte o omezení počtu entit v seznamu ve prospěch podrobnější informace, jež bude zobrazena.
Odpovídání na otázky (question answering)
Poskytněte odpovědi na otázky či dotazy v přirozeném jazyce s použitím technik jako semantické parsování a inference nad znalostní bází. Uvažte kontext položených otázek.