Vyjasnění hodnot, které se zobrazují ve statistikách navštěvnosti dotazů u našeho hledání.
Čas od času se na inetu rozjede debata, co vlastně znamenají čísla ve statistikách hledanosti dotazů na Seznamu; jako třeba teď zde. Rozhodl jsem se proto podat vám k tomu výklad, abyste už nemuseli dále tápat :-)
Čísla znamenají průměrný počet hledání konkrétního dotazu za určitou dobu.
Jako „hledání“ se bere zobrazení jedné stránky výsledku, čili pokud uživatel prohlédne první 3 stránky výsledku zobrazí se to jako 3 hledání. V číslech nejsou promítnuty roboti a další automatické scripty.
Dotazy prochází jednoduchou normalizací, aby se setřely rozdíly např. velká/malá písmena. Normalizace je: odstranění diakritiky, převedení na lower case a seřazení slov podle abecedy. Z hlediska statistik jsou tedy všechny dotazy vytvořené ze stejné množiny slov identické (to odpovídá zároveň na otázku, proč jsou slova v tabulce „Nejhledanější dotazy obsahující XY“ seřazena tak podivně). Z hlediska fulltextového vyhledávání jinak samozřejmě na pořadí a tvaru slov závisí.
Statistiky se počítají pro přesnou shodu (započítávají se dotazy tvořené právě zvolenou množinou slov), pro rozšířenou shodu (započítávají se dotazy, které tvoří nadmnožinu právě zvolené množiny slov) a pak se ještě agreguje tabulka nejčastějších rozšíření dotazu.
A teď k tomu co způsobuje nejčastější pochybnosti o věrohodnosti čísel :-) Na stránce statistik jsou zobrazeny dvě různé hodnoty, které se počítají ze dvou různě dlouhých období (tato informace bohužel ze statistik není úplně zřejmá; nějak to zkusíme upravit aby to dál už nemátlo…). Konkrétně:
- údaje návštěvnosti pro přesnou a rozšířenou shodu (tabulka napravo od grafu) jsou počítané jako průměr za posledních 60 dní (platí pro oba grafy; je vidět že graf pokrývá přesně 2 měsíce),
- tabulka nejčastějších rozšíření dotazů (na stránce statistik dole) je počítaná jako průměr za 14 dní. Sporný je právě první řádek tabulky (šedivě podbarven), který obsahuje průměrný údaj za 60 dní (zkopírované z horních grafů), kdežto zbytek tabulky jsou údaje za 14 dní. Správnější údaj jsme bohužel v tomto místě neměli k dispozici :-(
Čísla se liší tím více, čím dramatičtější změna v návštěvnosti byla v poslední době.
Příklad
Záměrně použiji stejný příklad „valentynské dárky“ jako ve výše zmíněné diskuzi u Michala Kubíčka. Nejprve statistiky návštěvnosti (datum 12. 2. 2009):
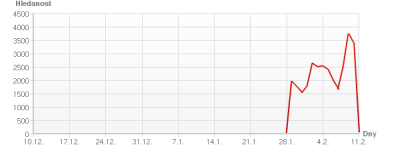
graf „přesná shoda“ pro dotaz „valentynské dárky„, průměr 485 hitů/den.
Průměr pro rozšířenou shodu je 895 hitů/den (graf opět podobný).
A teď jaký je rozdíl mezi těmito dvěma údaji pro „valentynske darky“ (pěkné obrázky jsem si vypůjčil z webu Michala Kubíčka):
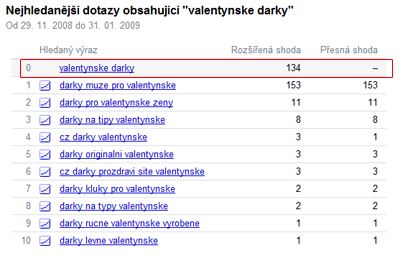
první řádek (viz předchozí text) jsou průměry za posledních 60 dní. Graf přesné shody pro valentynské dárky ale řiká, že návštěvnost se objevila pouze v poslední době, proto je dlouhodobější průměr tak nízký (hodnota menší jak 100 je indikována ‚-‚).
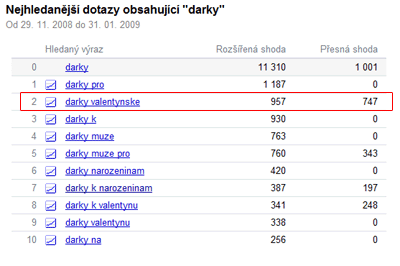
třetí řádek obsahuje krátkodobé průměry z konce ledna. Indikovaná návštěvnost je tak vysoká, protože „valentynske darky“ tou dobou dosahovaly cca 2000 hitů/den.
Hlavním účelem statistik je poskytnout jednoduše dostupný přehled v trendech návštěvnosti dotazů. Hodnoty se zobrazují pouze na hledacím webu a není z nich odvozováno nic dalšího. My je používáme ke své práci stejně tak jako vy :-)
Alternativní použití našeptávače pro odhad návštěvnosti nelze vůbec doporučit – jím udávané hodnoty dnes už vůbec nesouvisejí s reálnou hledaností. Našeptávač lze použít pouze pro porovnání dvou slov v našeptávači mezi sebou, víc nic.


