Dnešní díl seriálu naváže na předchozí motivační články a bude jako první z řady celý o sémantické analýze. Technika, kterou si dnes představíme se nazývá latentní sémantická analýza.
V předchozích článcích jsme se seznámili s vektorovými prostory pro reprezentaci textových dokumentů a představili si různé způsoby jejich zobrazení do těchto prostorů. Dále jsme si ukázali nejjednodušší způsoby snížení dimenzionality a zdůvodnili, proč je její snížení důležité.
Doposud jednotlivé dimenze odpovídaly slovům nebo shlukům slov se stejným základním tvarem. I přesto však zůstal počet dimenzí příliš vysoký. Techniky, které budou představeny v tomto a následujících článcích, jdou se shlukováním ještě dále. Dimenze zde spíše než slovům odpovídají takzvaným konceptům. Konceptem můžeme rozumět nějakou tématickou oblast, například technika, sport, kultura a podobně. Tyto koncepty však většinou nejsou vybírány ručně (neboť by byl jejich ruční výběr subjektivní a nereprezentativní), ale spíše automatickými metodami tak, aby co nejlépe korespondovaly s trénovacími daty. Jednotlivá slova potom nemusí patřit právě do jednoho shluku, ale typicky patří do více shluků s různými vahami. Například slovo „fotbal“ bude převážně spadat do konceptu „sport“, ale „vstupenka“ může stejnou měrou odpovídat konceptu „sport“ i konceptu „kultura“.
U automatických metod identifikace konceptů je klíčové předem učit jejich počet. Díky tomu lze nastavit granularitu konceptů. Pokud budou trénovací množinou obecné texty z různých oblastí a konceptů bude málo (řekněme 100), budou i výsledné koncepty obecné. Pokud však zvolíme počet konceptů desetkrát vyšší, obecné koncepty se nám rozbijí do jemnějších kategorií a např. místo konceptu „sport“ nám vzniknou koncepty jako „fotbal“, „hokej“, „tenis“ apod. Samozřejmě pokud trénovacími daty budou pouze sportovní texty, pro takovéto jemné členění nám bude stačit i 100 konceptů.
Pro vysvětlení latentní sémantické analýzy (LSA) se vraťme k příkladu z prvního dílu seriálu. Mějme kolekci tří dokumentů (pro zjednodušení je v každém dokumentu právě jedna věta):
- the man walked the dog
- the man took the dog to the park
- the dog went to the park
Jestliže vybereme všechna použitá slova a abecedně je seřadíme, dostaneme následující vektor slov:
[dog, man, park, the, to, took, walked, went]
Reprezentace dokumentů ve vektorovém prostoru frekvencí slov potom bude vypadat následovně:
- [1, 1, 0, 2, 0, 0, 1, 0]
- [1, 1, 1, 3, 1, 1, 0, 0]
- [1, 0, 1, 2, 1, 0, 0, 1]
Takový model však počítá pouze výskyty jednotlivých slov nezávisle na sobě. Latentní sémantická analýza oproti tomu pracuje i s informací o takzvaném souvýskytu dvou nebo více slov v dokumentu. Pokud se dvě slova vyskytují spolu ve stejných dokumentech častěji, než by odpovídalo náhodnému rozložení, jsou tato slova považována za sémanticky podobná. Například slova „fotbal“ a „sport“ se budou spolu v jednom dokumentu vyskytovat určitě častěji, než slova „fotbal“ a „kultura“. To je však jen souvýskyt první úrovně. Je dost možné, že se slova „fotbal“ a „tenis“ spolu na jedné stránce příliš často vyskytovat nebudou. Obě slova se však budou často vyskytovat se slovem „sport“. Díky tomu budou za sémanticky podobná považována i slova „fotbal“ a „tenis“. Tomu se říká souvýskyt druhé úrovně. Takových úrovní může být samozřejmě více, míra sémantické příbuznosti se však se stoupající úrovní souvýskytu snižuje.
Nyní se vraťme k našemu příkladu tří dokumentů. Pokud by dotazem bylo jediné slovo „walked“, měřeno cosinovou mírou by měl nenulovou podobnost s dotazem pouze dokument 1. Pokud však využijeme informace o souvýskytu, je vidět, že „walked“ je ve stejném dokumentu s „man“ a „man“ se v dokumentu 2 vyskytuje se slovem „took“. Stejný souvýskyt druhé úrovně platí i pro „walked“ – „dog“ – „took“. Díky tomu můžeme usuzovat, že slova „walked“ a „took“ by mohla mít podobný význam a podobnost dotazu „walked“ s dokumentem 2 bude tedy nenulová.
Latentní sémantická analýza je technika, která zobrazuje dokumenty a dotazy do prostoru latentních sémantických dimenzí, přičemž. slova, která jsou sémanticky podobná (měřeno mírou souvýskytů v dokumentech) jsou zobrazována do stejných dimenzí a slova sémanticky odlišná do různých dimenzí. Díky tomu mohou mít velkou sémantickou podobnost i dokumenty (případně dotaz a dokument), které spolu nesdílejí žádná slova.
Latentní sémantické dimenze odpovídají výše zmiňovaným konceptům, jsou však obtížně interpretovatelné. Jednou z možností, jak získat vhled do významu jednotlivých automaticky identifikovaných konceptů, je podívat se na slova, která jsou do daného konceptu (dimenze) zobrazována. Slova v LSA patří do jednotlivých konceptů s určitou vahou, pokud si tedy pro daný koncept vypíšeme slova s největší vahou, můžeme odhadnout, čemu daný koncept odpovídá. Např. dimenzi, která je reprezentovaná jako:
(1.5*„sport“ + 0.8*„fotbal“ + 0.7*„hokej“ + 0.7*„tenis“ + …)
lze považovat za koncept odpovídající lidsky interpretovatelné nálepce sport. Pokud nás však zajímá pouze sémantická podobnost dokumentů a slov, jednotlivé koncepty vůbec interpretovat nepotřebujeme.
Pro nalezení konceptů, příslušností slov ke konceptům a míry příslušnosti konceptů k dokumentům se používá matematická metoda nazývaná singular value decomposition. Jediným potřebným vstupem je kolekce dokumentů a počet konceptů, které chceme identifikovat. Výhodou latentní sémantické analýzy je, že určuje i váhy konceptů pro celou kolekci trénovacích dokumentů. Tedy pro každý koncept vrací i reálné číslo, které udává, jak moc je daný koncept v poskytnuté kolekci dokumentů významný. Díky tomu je možné koncepty s nejnižší vahou ignorovat a díky tomu dále snižovat dimenzionalitu sémantického prostoru. Lze matematicky dokázat, že chyba, ke které dojde při zanedbání konceptu s minimální vahou, je nejmenší možná.
Teorii latentní sémantické analýzy ani algoritmus nalezení konceptů zde popisovat nebudu. Případní zájemci z řad čtenářů se základní znalostí lineární algebry se o tom mohou dočíst např. v knize Foundations of Statistical Natural Language Processing nebo na Wikipedii.
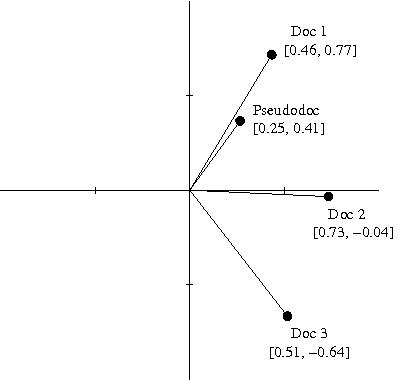
Na závěr se podívejme, jak budou vypadat naše dokumenty v dvoudimenzionálním latentním sémantickém prostoru, trénovaným pouze nad těmito třemi dokumenty. Do stejného prostoru je zobrazen i pseudodokument „the dog walked“, který se v trénovací množině nevyskytoval a slouží zde jako potenciální dotaz:
Je vidět, že pseudodokument je v našem sémantickém prostoru nejblíže dokumentu 1. Stejně by to dopadlo i v původním 8-dimenzionálním prostoru, zde nám ale stačily pouze 2 dimenze.
Latentní sémantická analýza řeší spoustu problémů, se kterými jsme se doposud v seriálu setkali. V první řadě významně snižuje dimenzi prostoru pro zobrazení dokumentů a dotazů. Pro většinu aplikací stačí dimenze do velikosti 1000. Další, již zmíněnou žádanou vlastností je, že dokáže pracovat se synonymy a významově podobnými slovy. V neposlední řadě, paradoxně díky nepřesnostem vzniklým redukcí dimenzionality, eliminuje šum a chyby v datech. Nevýhodou je však velká výpočetní náročnost a problém s víceznačností (v modelu latentní sémantické analýzy jsou považována všechna slova mající stejný zápis za stejnovýznamová).
V příštím dílu si představíme podobnou metodu redukce dimenzionality, která se nazývá Probabilistic Latent Semantic Analysis a je postavena na pravděpodobnostním přístupu.