Apache Avro je binární serializační systém, který podobně jako Protocol Buffers umožňuje serializování strukturovaných dat efektivním způsobem. Oba systémy jednoznačně poráží textově orientovanou serializaci jako je XML, JSON a podobné formáty, co do rychlosti i co do velikosti serializovaných zpráv. V čem je síla Avra a jak dopadne v porovnání s Protocol Buffer?
Serializace má mnoho využití například pro ukládaní dat do souboru. V tomto textu se zaměříme na serializaci pro výměnu zpráv mezi dvěma či více aplikacemi přes streamovací platformu Apache Kafka a s tím spojenou problematiku aktualizace aplikací, ve které nová aplikace musí být schopna zpracovávat zprávy zasílané ještě neaktualizovanou aplikací.
Protocol Buffers
Protocol Buffers byl veřejně publikován v roce 2008, dnes je mu tedy 10 let. Stejně jako Avro je jazykově neutrální a podporuje Javu, C++ a Python aj. Více o Protocol Buffers se lze dočíst na jeho domovské stránce. Zde se zaměřím pouze na binární reprezentaci serializace a kompatibilitu nutnou pro evoluci zasílaných serializovaných zpráv.
Jako příklad poslouží toto schéma:
syntax = "proto2";
message Person {
required string name = 1;
required int32 id = 2;
optional uint32 age = 3;
}
Čísla u jednotlivých položek představují jejich identifikátory zvané tagy. V rámci zprávy musí být tag unikátní. Toto schéma je určeno pro starší verzi Protocol Buffers. Identické schéma ve verzi Protocol Buffers 3 by vypadalo takto:
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
uint32 age = 3;
}
Jednou ze změn v Protocol Buffers verze 3 je, že všechny položky jsou nepovinné. Binární formát nicméně změněný nebyl, změna je jen v reprezentaci dat. Obě zprávy tak budou mít stejnou binární reprezentaci. Pro uvedenou strukturu:
Person {"Adam", 1, 18}
bude binární reprezentace následující, ať serializované ve verzi 2 či ve verzi 3:
[tag:1|string][string-size][Adam][tag:2|int32][1][tag:3|uint32][18] -> [0a][04][41 64 61 6d][10][01][18][12]
Tag je číslo, které se skládá z čísla položky a jejího typu. Všechna čísla, a tedy i tag, jsou serializována pomocí Varint enkodování (variable-length integer encoding) a pro tento konkrétní případ nebude délka serializovaného čísla či tagu větší než jeden byte. Pro větší čísla by samozřejmě délka narostla.
Verze schématu aktualizovaná o další položku by binární zprávu jen rozšířila o další dvojici tag a hodnota, kterou by aplikace zkompilovaná se starším schématem ignorovala.
Protocol Buffers používá schéma pro vygenerování kódu pro serializaci a deserializaci přímo pro konkrétní jazyk. Velkou výhodou Protocol Buffers je dopředná i zpětná kompatibilita během aktualizací schémat. Podpora pro aktualizaci schémat (přidání/ubrání položek) je zakomponovaná už v binárním formátu. Již jednou zkompilovaná aplikace se starším schématem bude umět číst novější zprávy a naopak. Kompatibilita funguje „by default“.
Apache Avro
Filozofie Avra je podstatně jiná. Cílí na rozsáhlé zprávy, ve kterých jsou dodatečné informace, jako je identifikace položky a její typ, zbytečný luxus, a výstupní binární formát obsahuje pouze data. Další výjimečnou vlastností jsou schémata v JSON formátu, která umožňují generické zpracování bez nutnosti generování kódu. Stejně jako u Protocol Buffers lze však ze schématu vygenerovat kód pro serializaci a deserializaci. Viz domovská stránka.
Použijeme podobný příklad zapsaný v Avro IDL:
record Person {
string name;
int id;
union { null, long } age;
}
Avro podporuje omezený počet typů, to znamená, že místo uint32 se musí použít 64 bitový long. Také přímo nepodporuje nepovinné položky a místo toho se požívá union, který má širší využití. Binární zpráva by vypadala takto:
[string-size][Adam][1][union index:1][18] -> [08][41 64 61 6d][02][02][24]
Stejně jako Protocol Buffers používá Avro Varint enkodování pro čísla, navíc s ZigZag enkodováním, které řeší neefektivitu Varint enkodování záporných čísel. Úspora oproti Protocol Buffers je minimálně 1 byte na povinnou položku, za vynechání tagu. Při velkých strukturách to může být nezanedbatelná úspora. Nicméně daní za to je fakt, že zprávu nejste schopni interpretovat bez znalosti schématu. S touto úsporou však nelze počítat v případě používání nepovinných položek, u kterých se vždy serializuje index unionu. Při větším množství nepovinných položek, které se neposílají, začíná být Protocol Buffers výhodnější, protože nepovinné položky neserializuje vůbec. Pro již zde použitý příklad, vynecháme-li při serializaci nepovinnou položku age, vypadá binarní zpráva takto:
[08][41 64 61 6d][02][00]
Při serializaci všech položek má zpráva serializovaná Protocol Buffers délku 10 byte a zpráva serializovaná Avrem má délku 8 byte. Při vynechání jedné nepovinné položky se zpráva serializovaná Protocol Buffers zkrátí o 2 byte a Avro zpráva se zkrátí pouze o 1 byte.
Avro je také dopředně i zpětně kompatibilní, nicméně nutnou podmínkou je znalost schématu zapsané zprávy a cílového schématu. U Protocol Buffers postačí jen cílové schéma. Zní to komplikovaně, demonstrujme si tedy čtení na příkladu. Aplikace zapisuje zprávy dle starého schématu a příjemce již používá nové schéma uvedené níže.
record Person {
string name;
int id;
union { null, long } weight;
union { null, long } age;
}
Při čtení se musí použít proxy objekt (v C++ je to ResolverSchema a v Java ResolvingDecoder), který načte zprávu podle prvního schématu, a příslušné položky přetřídí tak, aby odpovídaly schématu novému. Bez tohoto kroku by se načetla data z položky age do položky weight, protože data ze zprávy jsou interpretována pouze na základě schématu.
Jak tedy provádět aktualizace aplikací? V zásadě jsou možné dva přístupy. Aktualizovat zároveň producenta i konzumera, nebo posílat se zprávami i identifikátor schématu, kterým byly zapsané, a nějakým způsobem distribuovat i schémata. Druhý přístup praktické použití Avra jednoznačně komplikuje. Jednou z možností je použít již hotové řešení od Confluence, Schéma registry, které má REST API. Schéma registry pracuje dle následujícího schématu.
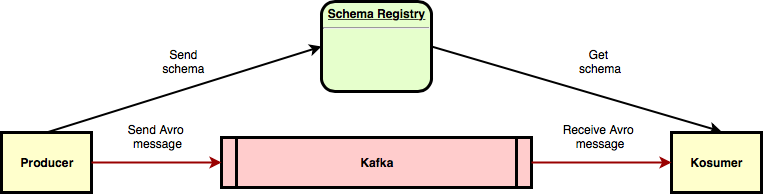
Je to poměrně jednoduchý server, ve kterém producent zaregistruje vlastní schéma. Následně obdrží jednoznačný identifikátor a tento identifikátor připojí na začátek každé své zprávy. Konzumer při přijetí zprávy dohledá schéma podle identifikátoru na serveru, schéma si stáhne a nakešuje, aby nemusel stahovat schéma pro každou zprávu. Confluence má připraveného klienta, který se postará o připojení identifikátoru před každou zprávu a při příjmu o stažení odpovídajícího schématu. Nicméně toto řešení je specifické pro distribuci zpráv přes Kafku.
Shrnutí
Avro je vhodné pro velké struktury, které nemají nepovinné položky, jinak se poměrně komplikované řešení nevyplatí. Dalším důvodem, proč vybrat Avro, je jednoznačně možnost serializovat bez nutnosti generovaní kódu a generického zpracování. Pro zbývající varianty, zejména pokud se jedná jen o serializaci a deserializaci, bude vždy jistější vybrat Protocol Buffers. V Skliku používáme Protocol Buffers pro posílání zpráv do Kafky, protože je pro naše zprávy úspornější a navíc nemá nároky na další komponenty, jako je schema registry.


