V pátek 29. ledna jsme do přirozeného vyhledávání nasadili největší změnu v technologii za posledních 10 let: hledání pomocí významových vektorů. Hledání webových stránek, které obsahují konkrétní slova, jsme teď rozšířili o hledání stránek, které mají podobný význam jako dotaz i přesto, že v nich některé z požadovaných slov chybí.
Vyhledávání na Seznamu dosud fungovalo převážně tak, že dotaz od uživatele opravíme, analyzujeme a přidáme k němu další slova, která by mohla pomoci najít to, co uživatel hledal. Takovými slovy mohou být skloňované tvary zadaných slov, synonyma, rozvinuté zkratky apod. Tato slova pak hledáme v zaindexovaných webových stránkách, nalezené stránky řadíme a vydáváme uživatelům. Vždy tedy zatím bylo potřeba na webové stránce (nebo ve zpětných odkazech) najít nějaký textový ekvivalent toho, co uživatel napsal do dotazu.
Je však řada dotazů, u kterých tato strategie nebyla dostatečně úspěšná. Těžké je třeba najít odpověď na dotaz zadaný v přirozeném jazyce. Čím víc slov uživatel do dotazu zadá, tím menší je pravděpodobnost, že se budou v nějakém tvaru vyskytovat všechna na jedné stránce. Každý si někdy nepamatujeme přesný název toho, co hledáme, nebo se nám povede zcela originální překlep. To všechno komplikuje práci vyhledávače, který se snaží slova z dotazu najít na webové stránce.
Pár příkladů:
- „jméno klavíristka jirečková“ – Záměr uživatele je zřejmý, chtěl znát křestní jméno klavíristky (asi do křížovky), jenže na stránkách, kde se o Noemi Jirečkové píše, přirozeně chybí slovo „jméno“.
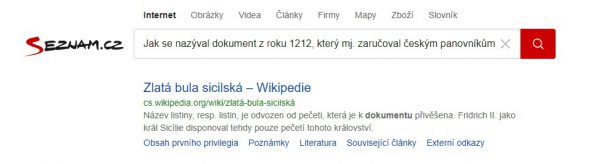
- „Jak se nazýval dokument z roku 1212, který mj. zaručoval českým panovníkům dědičný královský titul?“ – Taková otázka se možná hodí do písemky nebo AZ-kvízu, ale nalezení wikipedické stránky „Zlatá bula sicilská“ brání to, že na ní nenajdeme nic jako „nazýval“, „mj.“ ani „zaručoval“.
Jak na to? Ke stávajícím výsledkům jsme přidali vyhledávání pomocí významových vektorů. Z dotazů i webových stránek vyrábíme sadu vektorů, které reprezentují, co daný kus textu znamená. Vektory počítáme embeddingovým modelem, který je naučený přiřazovat podobné vektory textům, které se obvykle vyskytují v podobných kontextech. K vektorům dotazu pak hledáme nejpodobnější vektory stránek v mnohorozměrném vektorovém prostoru.
Voilà!
Podobnost významových vektorů je současně důležitým signálem pro řazení výsledků. Vedle nalezení nových stránek tak dojde i ke změnám pozic těch stávajících. Není to poslední změna v řazení pro nejbližší dobu. Tím, že nasazujeme novou technologii, se otevřel prostor pro další rozvoj a chystáme další vylepšování.
Navenek se změna projeví ještě tím, že teď pro téměř každý dotaz vydáme SERP plný výsledků. I pro hodně těžké a nesmyslné dotazy, kde bychom dříve konstatovali: „Bohužel jsem nic nenašel.“ V první řadě řešíme, aby uživatel i na těžké dotazy našel, co hledal. Až později budeme chtít omezit to, co nehledal.
Po této změně je i pro nás vyhledávání zase o krok větším blackboxem. Bude teď ještě těžší přijít na to, proč se která webová stránka ve vyhledávání objevila nebo neobjevila. Všechna měření před nasazením však slibují takové zlepšení přirozeného hledání, že nám to stojí za to.



