Umístění těch nejdůležitějších a nejzajímavějších výsledků na prvních horních pozicích je jedním ze základních cílů našeho Vyhledávání. Uspořádání výsledků je složitý problém, který vám přiblížíme v tomto seriálu. Začínáme malou podčástí, kterou je vkládání takzvaných upoutávek mezi ostatní výsledky.
Co jsou upoutávky?
Upoutávky se liší od ostatních výsledků vizuální stránkou a typicky nereprezentují pouze jednu webovou stránku, jako je tomu u klasických organických výsledků. Existuje několik různých druhů upoutávek. Například pro dotazy, u kterých je jedním z hlavních záměrů vidět vizuální podobu hledaného objektu, se může zobrazit obrázková upoutávka. Dalším příkladem může být upoutávka zboží zobrazující se pro dotazy, které se týkají nákupů, populární je také upoutávka Firmy.cz, která uživateli nabídne firmy a služby pohromadě.
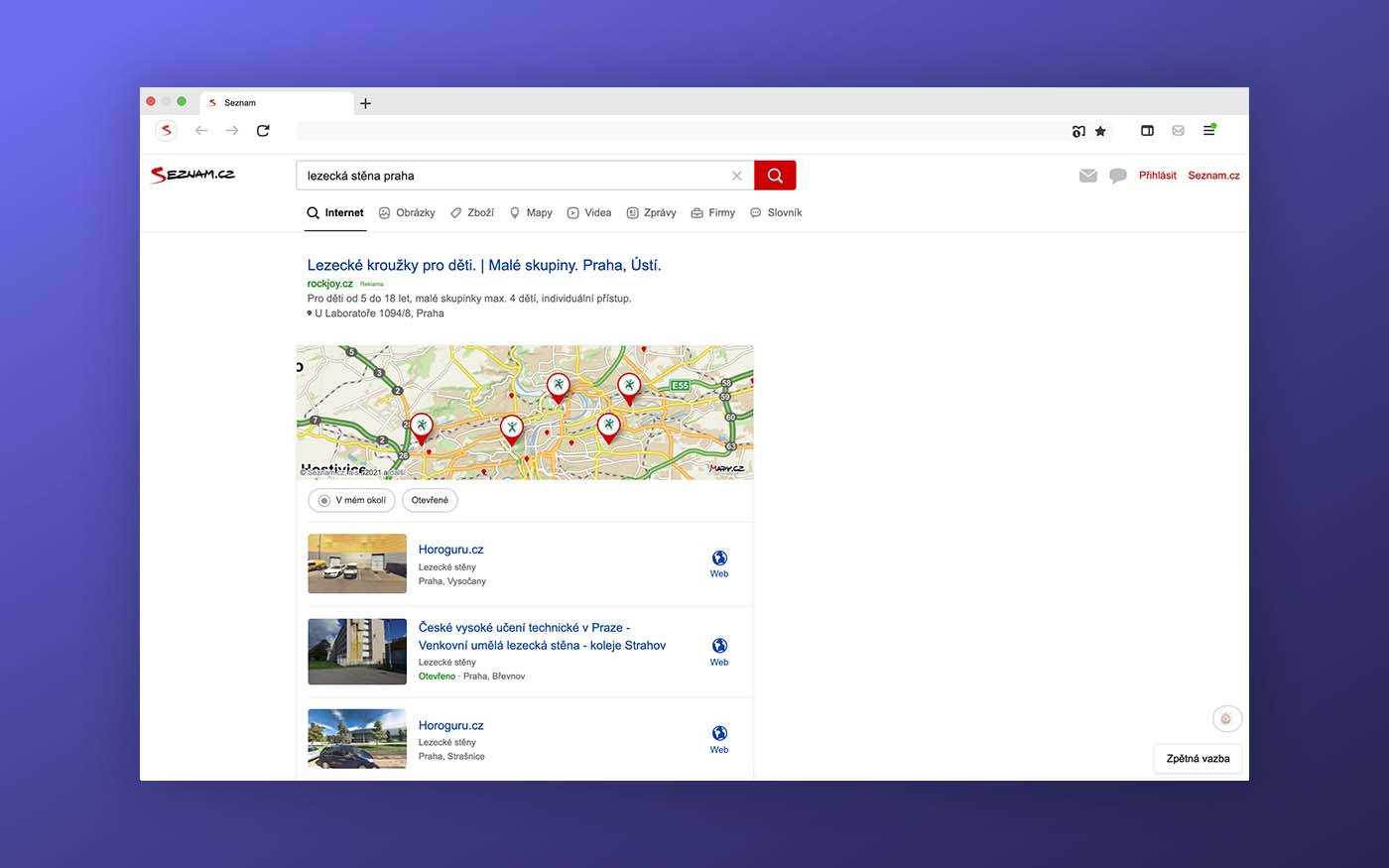
Příklad obrázkové upoutávky ve výsledcích Vyhledávání pro dotaz „plavecký hrad” Příklad upoutávky z Firmy.cz ve výsledcích Vyhledávání pro dotaz „lezecká stěna Praha”
Upoutávky umisťujeme jiným mechanismem než ostatní výsledky, u kterých v tomto článku budeme předpokládat, že jsou již správně seřazené a jejich pořadí je fixní. Tomuto mechanismu říkáme Alpaka. Její fungování a vlastnosti zde krátce popíšeme.
Jak Alpaka postupuje?
Abychom byli schopni určit dobré uspořádání výsledků, musíme umět poznat a změřit, které výsledky jsou pro uživatele nejlepší. Alpaka kvalitu výsledků aproximuje pomocí jejich klikanosti, tj. CTR(Click Through Rate), tedy pomocí poměru počtu kliků vůči počtu zobrazení výsledku. Čím je CTR vyšší, tím je pro Alpaku výsledek kvalitnější. CTR výsledků je vztažené ke kontextu, ve kterém se objevují. Pod kontextem si můžeme představit hlavně dotaz, na který se výsledek zobrazil. To znamená, že hodnota CTR stejného výsledku se typicky liší pro různé dotazy a díky tomu dokážeme podchytit skutečnost, že výsledek může být dobrou odpovědí na konkrétní dotaz, ale nemusí tomu tak být i pro jiné dotazy.
CTR výsledků v jejich kontextu typicky není známo. Některé dotazy jsou například hledány pouze jednou za celou historii hledání v Seznamu. Alpaka proto musí CTR odhadovat, k čemuž používá metodu strojového učení, která se učí z historických dat vyhledávání.
Alpaka při vkládání upoutávek postupuje jednoduchým způsobem. Začne na první pozici a odhadne CTR všech upoutávek, které prošly dřívějším výběrem, a také prvního organického výsledku. Vítěz je umístěn na první pozici a pokračuje se stejným způsobem na druhé pozici se zbývajícími výsledky. Ve chvíli, kdy se takto projdou všechny pozice, jsme s uspořádáním výsledků hotovi.
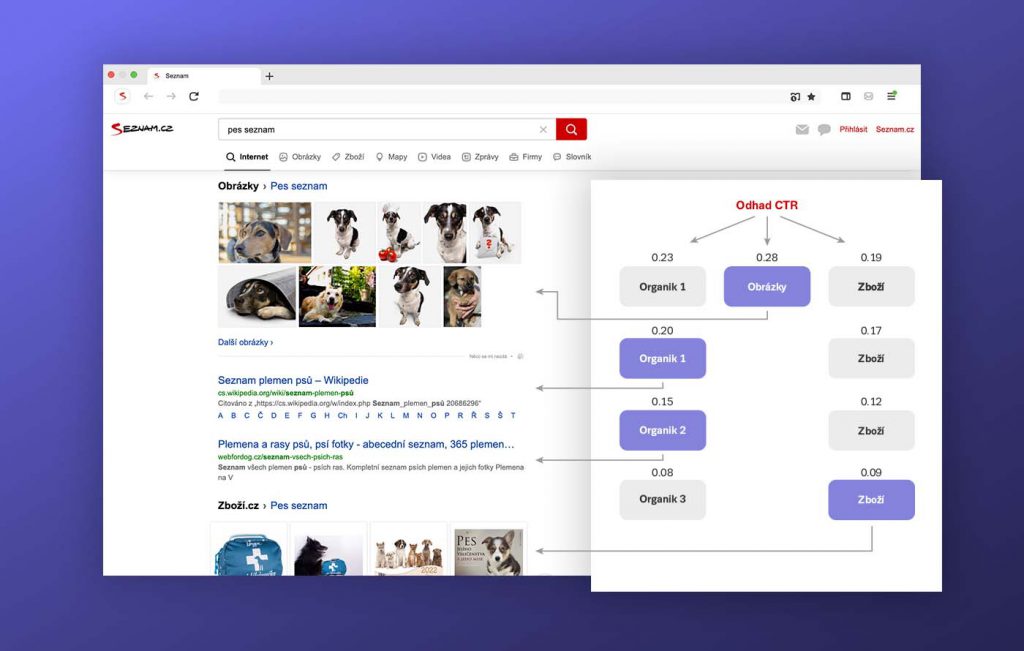
Obrázek výše uvádí příklad fungování Alpaky pro dotaz “pes seznam”. Na první pozici si konkurují organický výsledek 1, upoutávka Zboží.cz a upoutávka obrázků. Podle predikovaného CTR je zde umístěna upoutávka obrázků – očekává se nejvyšší proklikovost, uspokojení uživatele. Na dalších pozicích si konkurují organické výsledky a upoutávka Zboží.cz. Z pohledu predikovaného CTR vyhrává na druhé a třetí pozici organik, na čtvrté pak Zboží.cz.
Zajímavosti na závěr
Ne vždy je vybírání vítěze v klikanosti optimální volbou. Když se například zavede nový typ upoutávky, Alpaka ho nemusí dobře odhadnout, protože k němu nemá data pro učení. Kdyby ho nikdy nevyzkoušela umístit mezi výsledky, potřebná data se nenasbírají a jeho odhad se nikdy nezmění. Proto se vyplatí občas zkoušet i jiné výsledky než ty s nejvyšším odhadem, abychom k nim nasbírali data pro získání přesnějšího odhadu.
Data pro učení Alpaky jsou velká – obsahují miliardy příkladů pro učení. Odhad klikanosti zajišťuje logistická regrese.
Vstupem do logistické regrese je širší kontext než jen výsledek a dotaz. Alpaka umí brát v potaz například i informace o dalších výsledcích na stránce a informace o uživateli.
Možná se divíte, jak Alpaka přišla ke svému jménu. Alpaka je nástupcem Lamy. A zároveň odkazuje na náš dřívější Layout Manager (LaMa).
Celá Alpaka je postavená na predikci klikanosti – CTR. V příštím díle našeho seriálu si o CTR řekneme více, popíšeme jeho vlastnosti a budeme diskutovat jeho limity pro různé produkční aplikace, i pro námi projednávanou Alpaku.
Už více než 10 let internetové vyhledávače postupně mění svou funkci – z tradičního webového rozcestníku se posouvají do pozice zprostředkovatele obsahu s cílem odpovídat na uživatelské dotazy přímo. V Seznamu interně říkáme, že se vyhledávač proměňuje v odpovídač. Jaké kroky podnikáme, abychom tomuto trendu šli naproti, jak fungují naše AI sumarizace a co na to uživatelé?
17. října se uskutečnil už druhý ročník Seznam Meetupu zaměřeného na vývoj a praktické použití generativních jazykových modelů. Akce přilákala pestrou směsici technologických nadšenců, výzkumníků i odborníků z oblasti umělé inteligence. Meetup byl součástí Dnů AI 2024 a přinesl řadu inspirativních přednášek, praktických ukázek a networkingových příležitostí. O účast na akci, která proběhla v budově ČVUT i online, projevilo zájem bezmála 600 účastníků.
Vyhledávání informací na internetu se stalo nedílnou součástí našich životů. Ať už potřebujeme rychle zjistit, jak opravit zaseknutý zip, najít nejlepší kavárnu v okolí nebo vybrat dárek k narozeninám – internetové vyhledávače jsou často naší první zastávkou. A s rostoucí sofistikovaností technologií se mění i způsob, jakým s vyhledávači komunikujeme.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.