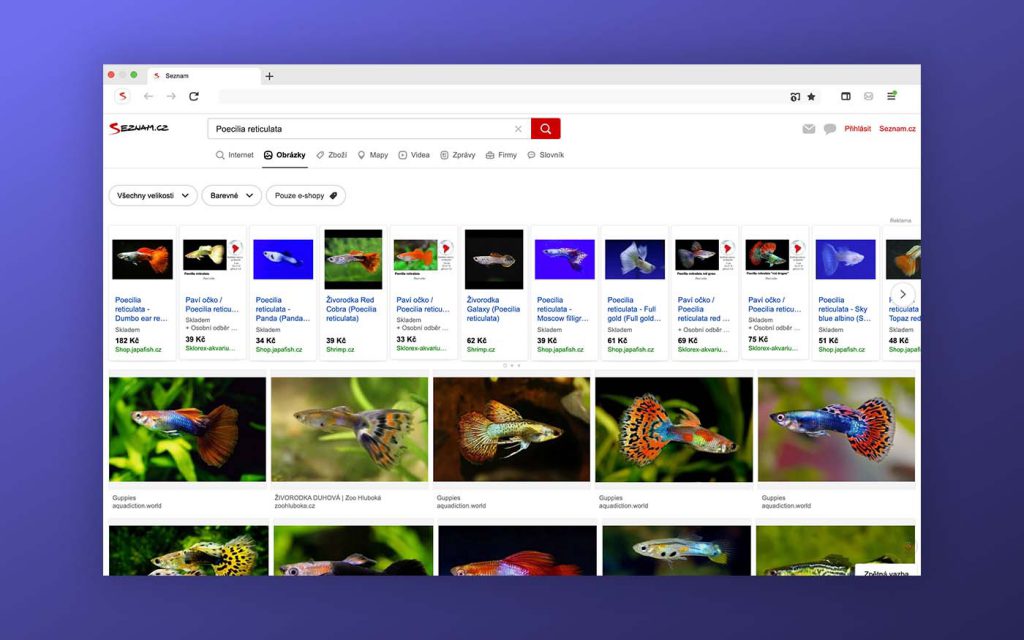
V posledním roce se v Seznamu intenzivně věnujeme zlepšování kvality vyhledávání v obrázcích. Naším cílem je, aby služba na dotazy uživatelů poskytovala kvalitnější a užitečnější obrázky.
Modernější neuronové sítě
Během března 2021 jsme zapojili první velkou aktualizaci modelu relevance. Spočívala v nahrazení konvoluční neuronové sítě ResNet za přesnější EfficientNet B4. Výstupem z této neuronové sítě je 1 792-dimenzionální vektor, který reprezentuje obrázek a jeho obsah. Relevanci tohoto obrázku k dotazu vyhodnocujeme modelem založeným na rozhodovacích stromech a knihovně Catboost. Podobně, jako v případě vyhledávání dokumentů. Kromě informací z neuronové sítě tento model k predikci relevance využívá i celou řadu dalších faktorů získaných například z textů, které se nacházejí v okolí obrázku v dokumentu nebo chování uživatelů na stránce s výsledky vyhledávání. K pochopení záměru uživatele přispívají vektory tvořené technologií FastText, která nahradila dříve používaný Word2Vec.
Od března 2021 neuronovou síť EfficientNet využíváme i pro určování vizuální kvality obrázků, která nově také ovlivňuje pořadí v SERPu (Search Engine Results Page – stránka výsledků zobrazená internetovým vyhledávačem). V srpnu jsme vyměnili model relevance za nový, naučený na výrazně větších datech. Díky tomu se podařilo vylepšit kvalitu například na dotazy na města.
Dále jsme v průběhu roku s využitím nové ML Ops platformy výrazně vylepšili proces získávání trénovacích dat. Díky tomu máme k dispozici data ve větší kvalitě a větším množství, než kdy dříve. Kromě hodnocení relevance anotátoři vybírají také kategorii, kam daný dotaz patří. Rozlišujeme například kategorie lidé, zvířata, města apod. Na kvalitu hledání v jednotlivých kategoriích se zaměřujeme odděleně.
Novinky v Obrázcích
Kromě vylepšování relevance jsme se zaměřili i na nové funkce. Jednou z nich jsou tzv. Produktové obrázky. Díky označení v SERPu je nyní snadné rozlišit, které obrázky pochází z e-shopů. Pro uživatele, kteří využívají službu pro nákupy, jsme také přidali filtr “pouze e-shopy”.
Během roku se nám postupně podařilo hledání v obrázcích vylepšit o několik procentních bodů. Uživatelé v porovnání s předchozím rokem častěji najdou, co měli na mysli.
Aktuálně pracujeme na zvýšení pokrytí s využitím výběru obrázků z indexu pomocí vektorové podobnosti a na rychlejší aktualizaci indexu, aby bylo hledání v obrázcích užitečnější i pro hledání aktuálních událostí.
Už více než 10 let internetové vyhledávače postupně mění svou funkci – z tradičního webového rozcestníku se posouvají do pozice zprostředkovatele obsahu s cílem odpovídat na uživatelské dotazy přímo. V Seznamu interně říkáme, že se vyhledávač proměňuje v odpovídač. Jaké kroky podnikáme, abychom tomuto trendu šli naproti, jak fungují naše AI sumarizace a co na to uživatelé?
17. října se uskutečnil už druhý ročník Seznam Meetupu zaměřeného na vývoj a praktické použití generativních jazykových modelů. Akce přilákala pestrou směsici technologických nadšenců, výzkumníků i odborníků z oblasti umělé inteligence. Meetup byl součástí Dnů AI 2024 a přinesl řadu inspirativních přednášek, praktických ukázek a networkingových příležitostí. O účast na akci, která proběhla v budově ČVUT i online, projevilo zájem bezmála 600 účastníků.
Vyhledávání informací na internetu se stalo nedílnou součástí našich životů. Ať už potřebujeme rychle zjistit, jak opravit zaseknutý zip, najít nejlepší kavárnu v okolí nebo vybrat dárek k narozeninám – internetové vyhledávače jsou často naší první zastávkou. A s rostoucí sofistikovaností technologií se mění i způsob, jakým s vyhledávači komunikujeme.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.