V posledním článku o doporučovacích systémech jsme vyzdvihli schopnost doporučovacích systémů (DS) výrazně zvýšit úroveň nabízených služeb, díky které v posledních letech pronikly do všech oblastí, kde jsou obsah nebo služby nabízeny koncovým uživatelům. Metody strojového učení, které se v DS využívají, jsou ze stejného důvodu předmětem pokročilého výzkumu v mnoha prestižních technologických společnostech. V tomto postu se budeme věnovat tomu, jak DS pracují a jaké technologie stojí za jejich úspěšným rozšířením.
Ještě než se pustíme do výkladu, rádi bychom Vás upozornili na událost, která může zajímat kohokoliv, kdo se chce dozvědět více o DS technologiích a o vědeckém výzkumu, který za vývojem DS stojí: V květnu tohoto roku společnost Seznam.cz pořádá workshop v anglickém jazyce s názvem „Recommendation Systems and User Representations” na vědecké konferenci ML Prague 2022. Účastníci setkání se mají možnost seznámit se současným stavem výzkumu doporučovacích systémů, a to včetně architektur hlubokých neuronových sítí používajících doporučovací systémy. Součástí semináře bude praktická část, v rámci které si zájemci budou schopni natrénovat hlubokou neuronovou síť. Na tu následně aplikují řešení problému doporučování zpráv na připravených datových sadách. Výklad i empirická část se zaměří na řešení vybraných praktických problémů doporučování, zejména řešení tzv. „cold start” problému pomocí metod reprezentace uživatele.
Práce DS začíná v momentě, kdy uživatel zahájí používání online služby, a předtím, než učiní rozhodnutí, jakou konkrétní položku služby si vybere. Například při čtení zpráv na zpravodajském portálu jde o výběr článku k přečtení. V tento moment stránka služby pošle DS požadavek, třeba ve formě vyhledávacího dotazu, nebo ve formě HTTP requestu na zobrazení stránky s konkrétním obsahem. Zůstaneme-li u příkladu zpravodajského portálu, může jít o stránku s článkem, který si uživatel vybral k přečtení. Výstupem DS vygenerovaným na základě požadavku a na základě dat, která má k dispozici, je poté seznam položek, které DS uživateli doporučuje k výběru, například seznam dalších článků, které mohou uživatele zajímat. Seznam odkazů na doporučené zprávy se potom vloží do obsahu uživatelem navštívené stránky, třeba do prostoru pod článkem.
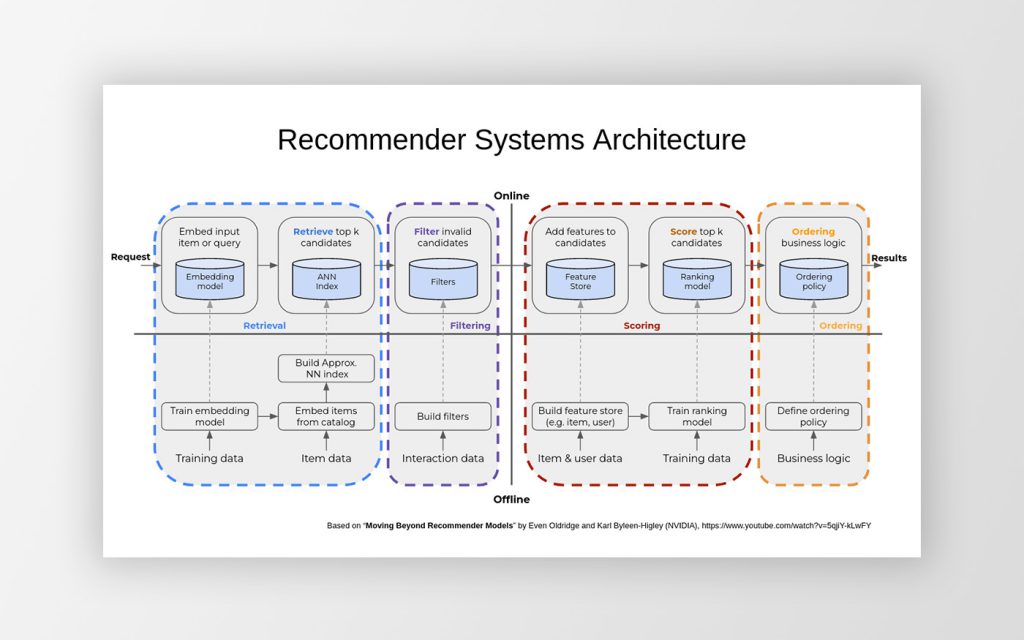
Činnosti, které typický DS provede, aby ze vstupního požadavku vytvořil výstupní seznam doporučení, se obecně mohou rozdělit do čtyř hlavních stupňů: předvýběr, filtrování, skórování a řazení.
Předvýběr (Retrieval) řeší úlohu rychlého zúžení nabídky položek na základě vstupního požadavku. Položek, které služba uživateli může v daný moment nabídnout, můžou být desetitisíce (články na zpravodajském portálu), až miliony (produkty ve velkém online obchodu) a v reálném čase DS nemusí podle uživatelských preferencí ohodnotit úplně každou. DS totiž musí uživateli svá doporučení dodat (typicky) do několika desítek milisekund od obdržení požadavku. DS proto provede rychlý předvýběr položek, typicky použije model natrénovaný některou metodou strojového učení s použitím historických dat, který popisuje pravděpodobnost výběru položek na základě vybraných parametrů požadavku (například zúžení výběru článků na základě podobnosti k článku, který si uživatel přečetl naposledy). Výsledný seznam předvybraných položek může obsahovat stovky až tisíce položek, počet, který již umožňuje dalším fázím DS vyhodnotit každou položku zvlášť v požadovaném časovém intervalu.
Filtrování (Filtering) provede vyřazení položek (ze seznamu předvybraných položek vytvořeného ve stupni předvýběr) aplikací jednoduchých pravidel (například vyřazení článků které uživatel již přečetl). Modelování jednoduchých pravidel pomocí metod strojového učení obvykle není efektivní a použití jednoduchého filtru je v jejich případě jednodušší, rychlejší a účinnější.
Skórování (Scoring) použije model, který byl naučen na základě historických dat, tentokrát ovšem s tím rozdílem, že vezme v úvahu všechny relevantní informace ze vstupního požadavku a všechny relevantní údaje o uživateli a vyhodnotí každou položku filtrovaného seznamu položek tak, že každé z nich přiřadí skóre. Výstupní skóre položky je v ideálním případě úměrné uživatelově zájmu o danou položku, a tedy odráží uživatelskou osobní preferenci při výběru položek služby. Příkladem jednoduchého odhadu uživatelské preference je pravděpodobnost prokliku, která může být modelována na základě záznamů o uživatelových aktivitách.
Řazení (Ordering) bere v úvahu skóre položek na výstupním seznamu předchozího stupně a použije ho k seřazení položek před jejich vydáním na výstup DS. Na tomto stupni typicky proběhne konečné zúžení počtu položek na základě pravidel vyplývajících z business logiky služby, v případě zpravodajského portálů se typicky provede výběr několika doporučovaných článků, které mají nejvyšší skóre.
Jak je čtenáři již zřejmé, klíčovými částmi DS jsou modely, které provádějí předvýběr a produkují skóre ve stupni skórování. Kvalita a efektivita těchto modelů určují úspěch nebo neúspěch výsledných doporučení a tím i výslednou uživatelskou spokojenost. Pro vytváření modelů se používá sofistikovaných metod strojového učení, jako jsou zobecněné lineární modely, kolaborativní filtrování, (hluboké) neuronové sítě. Metody strojového učení v DS jsou předmětem kontinuálního výzkumu a průběžného zdokonalování.
Neustále pracujeme na tom, aby se ve Vyhledávání na Seznamu zobrazovaly co nejlepší výsledky. I proto jsme nedávno nasadili úpravy, které zlepšují relevanci organického hledání. Co se změnilo a z čeho úpravy vycházejí?
Uživatelé očekávají, že s pomocí vyhledávače najdou na internetu informace, které zrovna potřebují. Aby však vyhledávač mohl na jejich dotaz správně odpovědět, musí udržovat na svých serverech lokální kopii webu, kde nesmí žádná důležitá webová stránka chybět. Navíc by všechny měly být ve stejném stavu, jako na internetu. Databázi pro vyhledávač tvoří vyhledávací robot, který …
ACM SIGIR (Special Interest Group on Information Retrieval) je konference, která se zabývá pořízením, organizací, ukládáním, vyhledáváním a šířením informací – a to všechno z teoretického a praktického pohledu.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.