V minulém článku jsme shrnuli základy A/B testování. Jak ale rozdělíme uživatele do testů a co určitě zkontrolovat předem, abychom dosáhli relevantních výsledků? Jedině prvotní správné zadávání nám totiž zaručí i správné výsledky. Pojďme se tedy blíže podívat, co (ne)dělat.
Abychom mohli vyvozovat z A/B testů závěry, potřebujeme se spolehnout na jejich správné zadání. Musíme tedy zajistit, aby jediný rozdíl mezi variantami A/B testu byla pouze testovaná změna a nevstupovaly tam další vlivy, které ovlivní chování lidí. To je ovšem obecně docela tvrdý oříšek. Pojďme se spolu podívat, jakými způsoby na něj vyzráváme v Seznamu.
Více testů zároveň
Jedním z požadavků na zadávání našich A/B testů je, abychom dokázali spouštět co nejvíce testů zároveň. Současně ale potřebujeme mít kontrolu, jak jsou lidé rozřazeni do aktuálně běžících experimentů. Určité testy totiž nemusí být navzájem kompatibilní. Pokud např. u jednoho experimentu změníme barvu textu na zelenou a u druhého testu pozadí stránky taktéž na zelenou, tyto testy se navzájem ovlivní a výsledky nebude možné jasně interpretovat.
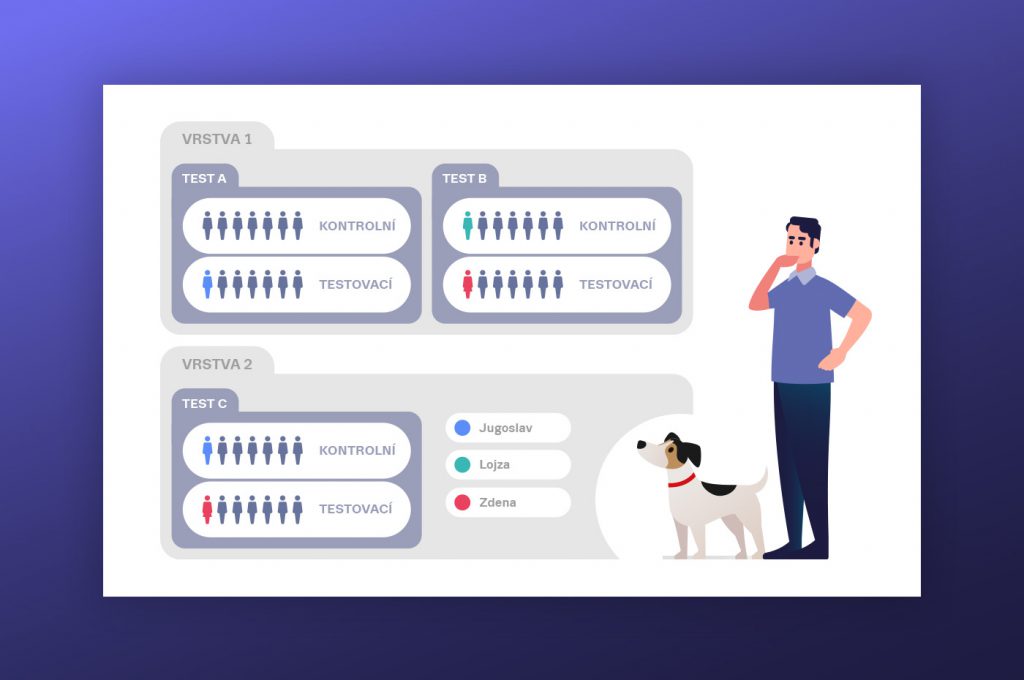
V divizi Vyhledávání používáme dělení na vrstvy. Každý jednotlivý test je podle pravidel umístěn do vybrané vrstvy. V rámci vrstvy máme zajištěno, že se člověk účastní pouze jednoho experimentu v daný okamžik. Takové nastavení nám dává možnost testovat více experimentů najednou na určitém uživateli, ale zároveň přináší jistotu, že se spolu nepotkají nekompatibilní experimenty.
Nákres rozdělení uživatelů do různých testů ve vrstvách.
Zde platí, že uživatel nemůže být ve více testech jedné vrstvy a nemusí být ani v určitém testu každé vrstvy. Pouze pro srozumitelnost tohoto obrázku přidáváme k panáčkům jména, se kterými samozřejmě u uživatelů nemůžeme pracovat.
Kyblíkování
Při přidělování lidí do testu je důležité, aby lidé z jedné varianty určitého experimentu netvořili významnou část jiné varianty u dalšího experimentu. Pak by při vyhodnocování mohlo dojít k tomu, že výsledky jednoho testu ovlivní výsledek druhého. Pro tyto účely využíváme takzvané kyblíkování uživatelů. V každé vrstvě je vytvořeno 1 000 kyblíků podle určitého klíče. Klíče jsou mezi vrstvami vždy unikátní, což zajistí, že uživatel je pro každou vrstvu umístěn vždy v jiném kyblíku. Každému návštěvníkovi, který poprvé vstoupí na Vyhledávání Seznamu, vygenerujeme unikátní ID, které mu následně uložíme do cookie. Na základě tohoto ID vždy pro každou vrstvu vybereme deterministicky jeden kyblík, do kterého uživatel spadá. Podle vybraných kyblíků jsme poté schopni určit, zda a v jakých A/B testech se uživatel nachází. Tato implementace zajišťuje rovnoměrné rozdělení lidí mezi vrstvami a experimenty.
Kontrola rozložení
Po samotném kyblíkování používáme ještě kontrolu rozložení. I když jsou uživatelé do kyblíků přiřazováni náhodně, je možné, že se takto sestavená skupina chová jinak, než skupina uživatelů z jiného kyblíku. Proto kontrolujeme chování uživatelů ve vybraných kyblících mezi jednotlivými variantami podle sady určitých metrik. Hodnoty pro tyto metriky vypočítáváme z období za posledních 30 dní. Pokud se metriky mezi variantami liší, přejdeme k výběru nových kyblíků a jejich opětovnému porovnání. Toto se opakuje do té doby, než najdeme shodu ve všech metrikách.
Jak dlouhý experiment má smysl?
Další pastí při spouštění A/B testů je jejich nedostatečná délka. Pokud jsou experimenty vyhodnocovány průběžně, může se v prvních dnech testu ukazovat, že výsledky předčily očekávání, nebo že se jedná o obrovský propadák. První dny testu ovšem nejsou většinou vypovídající. Doporučená doba experimentu je minimálně jeden byznys cyklus. Ten se liší podle produktu, ale ve většině případů představuje jeden celý týden. Týdenní období využíváme pro své testy i my – víme, že lidé hledají určité dotazy v pracovním týdnu a jiné o víkendu. Stejně tak se mění i jejich chování na stránce s výsledky.
Než přejdeme k vyhodnocení
Předtím, než se vrhneme na samotné vyhodnocení, doporučujeme probrat ještě jednu funkcionalitu, kterou u nás využíváme. Jak jsem popsal výše, naše platforma pro zadávání A/B experimentů náhodně vybere skupinu lidí a ty přiřadí do určité varianty testu. Pokud experiment testuje třeba vizuální změnu počasí, může se stát, že několik uživatelů vlastně danou změnu nikdy neuvidí, jelikož v průběhu testu nehledají předpověď počasí. Proto si k testu vyfiltrujeme pouze uživatele, kteří změnu viděli. K tomu využíváme takzvaný feature hit, o kterém se dozvíte více v dalším článku.
Uživatelé v Česku na portálu Sauto.cz nejčastěji vyhledávají automobily spalující benzín*. Současná situace na trhu s palivy ale mnoho lidí, podle dat Seznam.cz Vyhledávání, podněcuje k většímu zájmu o elektroauta. Roste také počet dotazů na ceny benzínu, zejména na čerpacích stanicích Ono. Na Zboží.cz mají lidé větší zájem o kanystry, většinou o ty o objemu 20 litrů. Podíváme-li …
Česká internetová jednička tradičně zveřejnila svoje skokany vyhledávání – výrazy, jejichž hledanost ve srovnání s předchozím rokem vyrostla nejvíce. Mezi častěji zadané dotazy patřily ty na filmovou a seriálovou tvorbu. Konkrétně této kategorii loni kralovala česko-slovenská komedie s názvem Villa Lucia. Na čelní místo žebříčku více hledaných výrazů týkajících se volnočasových aktivit se probojovalo Námořní muzeum …
Page Quality je jedním z nejdůležitějších faktorů, které rozhodují o viditelnosti vašeho webu ve vyhledávání. Nejde jen o technickou metodu hodnocení, ale o souhrn principů, které určují, jak kvalitní, důvěryhodná a uživatelsky přívětivá vaše stránka skutečně je. Zjistěte, co vše Page Quality ovlivňuje a jak můžete její úroveň zvýšit, abyste posílili pozice svého webu v SERPu i důvěru uživatelů.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.