V loňském roce jsme vylepšili detekci lokalit v textu. Rozpoznávat lokality chceme nejen v dotazech, které uživatelé pokládají napříč našimi službami, ale například i v textech webových stránek. Jak lokality detekujeme, k čemu je dále využíváme a proč záleží na tom, kde se při zadávání dotazu uživatel zrovna nachází?
Španělský ptáček v lednici
Nejprve je nutné stanovit, co je a není lokalita. Lokality jsou konkrétní adresy, ulice, obce, státy, hrady, zámky, jeskyně, hory, řeky, ledovce a mnoho dalších politických a geografických útvarů, dopravních a inženýrských staveb i bodů zájmu. Možná pro někoho bude překvapením, že lokalitou může být i poštovní směrovací číslo, studánka nebo třeba silnice.
Lokalitu bychom ale naopak nehledali ve „španělském ptáčkovi“, „kladenské pečeni“, nebo třeba „sektorovém nábytku London“, i když na první pohled se část dotazu jako lokalita může zdát.
Samostatnou kategorií jsou slova, která mění význam v závislosti na kontextu – v dotazu „jak postavit hrad z písku“ lokalitu nenajdeme, zatímco v dotazu „hrad poblíž Písku“ už ano.
Obdobně jsou na tom i slova, která svůj význam vyjadřují velkým počátečním písmenem. „Španělský ptáček v Lednici” se pravděpodobně nenachází v chladničce potravin, ale spíš v Jihomoravském kraji. Navíc uživatelé při zadávání dotazu do vyhledávače často nepoužívají velká a malá písmena, která by nám pomohla význam rozlišit.
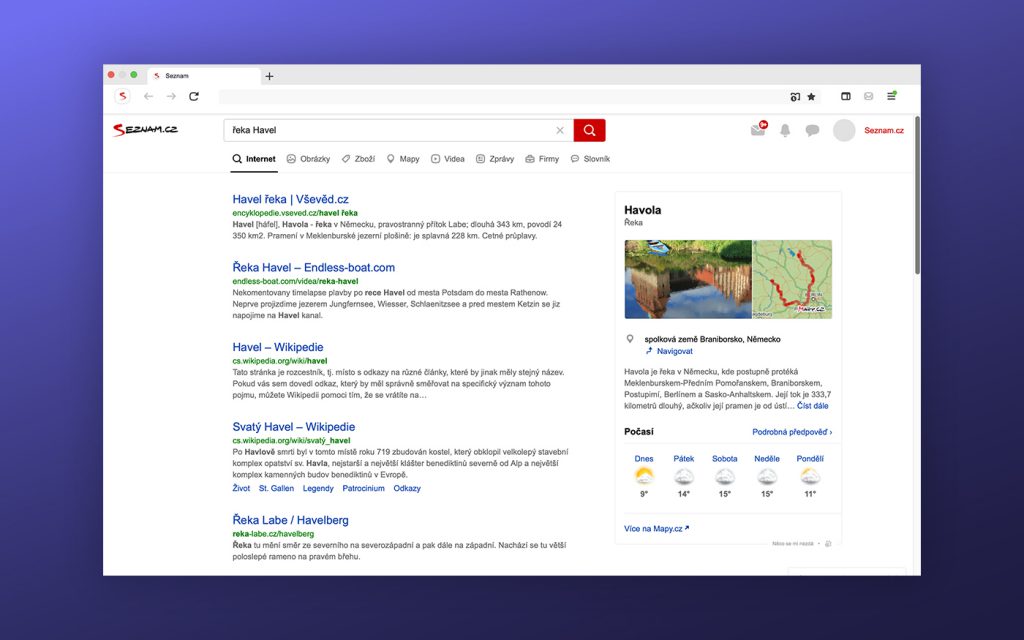
A pak jsou tu třeba i slova, která mají vždy velké písmeno, ale mohou mít různý význam – „kam ústí řeka Havel” lokalitu označuje, zatímco „Havel disident” a „kdy má svátek Havel” nikoliv.
Mravenčí práce anotátorů
Jakmile jsme stanovili, co je a není lokalita, a promysleli jsme, v jakých kontextech se mohou lokality nacházet a jaká úskalí to s sebou přináší, pustili jsme se do přípravy dat pro učení jazykového modelu.
V našem případě to znamenalo připravit dotazy z Vyhledávání Seznam.cz a tam, kde to bylo možné, přidat i informaci, kde se uživatel zrovna nacházel, když dotaz zadával.
Díky tomu jsme mohli rozhodnout případy lokalit, které nemají jedinečný název. Je důležité, zda uživatel, který hledá odpověď na dotaz „obecní úřad Uhřice”, právě stojí poblíž Jevíčka, Vimperku, Prčic nebo Žďánic.
Anotátoři prošli všechny připravené dotazy a označili, zda se v nich vyskytuje lokalita, nebo ne. Například v dotazu „chata pod mravenečníkem” našli existující lokalitu ve slově „mravenečníkem” a označili lokalitu Mravenečník (1344 m) na mapě.
Od Štatlu až po Valmez
Anotovaná data jsme následně použili k natrénování jazykového modelu. Ten věděl, jak se v jednotlivých dotazech rozhodl anotátor, a naučil se rozhodovat obdobně, zohledňovat kontext i to, kde se uživatel zrovna nachází, pokud nám takovou informaci povolil zpracovat.
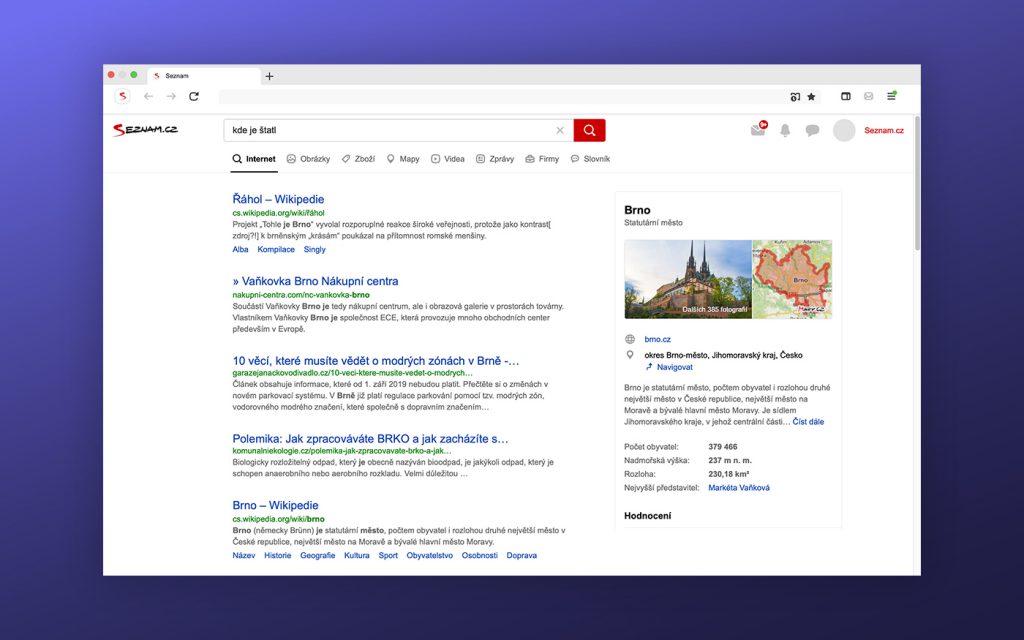
Obrovský přínos do detekce lokalit vnesla služba Mapy.cz, která vytváří a spravuje databázi lokalit celého světa. Z ní čerpáme GPS souřadnice, informaci, o jaký typ lokality se jedná, v jaké zemi se nachází, ale třeba také její další názvy, a to i hovorové – snadno tak poznáme, jaké město měl uživatel na mysli, když vyhledal Štatl nebo Valmez.
S novou detekcí lokalit a všemi informacemi pracujeme napříč různými službami Seznam.cz – ve Vyhledávání, ale například také na službách Sbazar, Sauto, Volnamista.cz a v mnoha dalších.
Kde ale můžete detekované lokality vidět vy? Například ve vyhledávání u dotazů:
Jak vypadá detekce lokalit ve vyhledávání už víte, ale možná vás ještě zajímá, jak si vede v číslech. Na anotovaných datech můžeme vyhodnotit, zda najdeme lokalitu všude, kde ji označili anotátoři – to se nám daří téměř v 90 % případů.
Detekci lokalit stále vylepšujeme, upravujeme pro jednotlivé služby Seznam.cz a hledáme další možnosti, jak ji ještě zdokonalit. V poslední době jsme se například zaměřili na lepší detekci poštovních směrovacích čísel nebo třeba detekci lokalit v textech webových stránek.
Jak slaví Vánoce v Rakousku a kdy je nejlepší čas navštívit Zanzibar? Už nemusíte brouzdat internetem a pracně získávat informace. Naše Vyhledávání to rádo udělá za vás. Díky nové funkcionalitě sumarizací vám informace poskládá do jedné ucelené odpovědi a ke každé větě transparentně přidá i zdroj. Začínáme pozvolna, ale postupně pokrytí novinky rozšiřujeme.
17. října se uskutečnil už druhý ročník Seznam Meetupu zaměřeného na vývoj a praktické použití generativních jazykových modelů. Akce přilákala pestrou směsici technologických nadšenců, výzkumníků i odborníků z oblasti umělé inteligence. Meetup byl součástí Dnů AI 2024 a přinesl řadu inspirativních přednášek, praktických ukázek a networkingových příležitostí. O účast na akci, která proběhla v budově ČVUT i online, projevilo zájem bezmála 600 účastníků.
Seznam interně vyvíjí velké jazykové modely nazvané SeLLMa (Šelma), které mohou v mnohém konkurovat komerčně dostupným modelům. Diana Hlaváčová hostům Seznam fóra představila, co naše jazykové modely umí a v jakých produktech je využíváme.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.