V dnešním dílu seriálu o sémantické analýze textů, který je posledním v řadě, využijeme znalostí z předchozích dílů a ukážeme si několik praktických příkladů aplikací, ve kterých lze úspěšně reprezentace významu pomocí vektoru témat využít.
Nejprve si shrňme potřebné výchozí znalosti, nabyté z předchozích článků. V zásadě jsme si představili tři přístupy k určení významu dokumentu (ve skutečnosti se může jednat o libovolnou tematicky ucelenou část textu, pro jednoduchost ji ale dále budeme označovat jako dokument) pomocí vektoru témat – Latentní sémantickou analýzu (LSA), Pravděpodobnostní latentní sémantickou analýzu (pLSA) a Latentní Dirichletovskou alokaci (LDA). Ve všech třech případech je význam reprezentován vektorem v n-dimenzionálním vektorovém prostoru, kde každá dimenze odpovídá jednomu tématu a příslušnost k němu je vyjádřena reálným číslem. Nalezení takových vektorů pro předem danou množinu dokumentů probíhá ve fázi učení, ke kterému je třeba znát pouze požadovaný počet dimenzí. Ve všech třech případech se jedná učení bez učitele, v případě LSA a LDA je dokonce možné s využitím natrénované množiny dokumentů efektivně odvodit témata i pro předem neznámé dokumenty.
Důležitou otázkou, která doposud nebyla uspokojivě zodpovězena, je způsob výběru vhodného počtu témat. Dá se říci, že větší počet témat znamená jemnější granularitu významů a současně větší nároky na výpočetní čas. Obecně platné pravidlo pro nalezení vhodného počtu témat však neexistuje. Vždy je počet témat ovlivněn minimálně dvěma faktory – použitými daty a konkrétní aplikací. Pro obecné korpusy, kde jsou zastoupena všechna témata, která se vyskytují na internetu, se nám při různých experimentech nejlépe osvědčily hodnoty v řádu stovek. Nejlepším způsobem výběru je vykoušení několika hodnot pro konkrétní data a aplikaci. Je však dobré si uvědomit, jak zhruba počet dimenzí kvalitu aplikace ovlivňuje. Následující graf zobrazuje závislost kvality relevance hledání dokumentů v korpusu biomedicínských textů pomocí metody LSA:
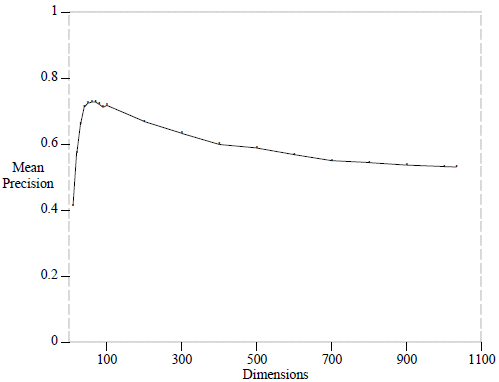
Přesný popis metody měření kvality lze najít v původním článku Enhancing Performance in Latent Semantic Indexing. Z grafu je dobře vidět, že přesnost rychle roste k počtu dimenzí kolem 100 a dále už jen postupně klesá až k počtu dimenzí, který je roven počtu unikátních slov ve všech dokumentech. Podobné chování lze vysledovat i v ostatních aplikacích.
Nyní se již můžeme posunout k představení možných aplikací metod, popsaných v předchozích článcích. Výčet nemá v žádném případě ambice postihnout všechny aplikace, ať už potenciální nebo praxí osvědčené. Rovněž zde neprozradím, kde a jakým způsobem používáme metody sémantické analýzy textů v Seznamu. Výčet možných aplikací je výčtem mně známých problémů, kde byly tyto metody úspěšně použity. Je na laskavém čtenáři, aby ho tyto příklady motivovaly k použití pro řešení jeho vlastních problémů.
- Information retrieval – nejznámější, a zde již mnohokrát zmiňovanou aplikací, je fulltextové vyhledávání. Veškeré prohledávané dokumenty, stejně tak jako kladené dotazy, jsou reprezentovány pomocí vektorů témat a tyto vektory jsou následně porovnávány. Výsledky jsou potom seřazeny např. podle velikosti úhlu, který svírá vektor dotazu a vektor dokumentu. Dokumenty samozřejmě nemusí být řazeny výhradně podle úhlu, lze ho využít jen jako jedno z mnoha kritérii, která ovlivňují seřazení dokumentů.
- Jazykově nezávislé vyhledávání – vzhledem k tomu, že jsou všechny popsané metody jazykově nezávislé, lze je použít i pro vyhledávání napříč různými jazyky. Je potřeba pouze vytvořit jazykově nezávislý sémantický prostor. Jeden ze způsobů jak toho dosáhnout popisuje např. článek Automatic Cross-Language Retrieval Using Latent Semantic Indexing. Autoři vytvořili trénovací množinu spojením přeložených textů ve více jazycích do jednoho dokumentu. Díky tomu výsledné dimenze odpovídaly jazykově nezávislým konceptům.
- Klasifikace textů – Další přímočarou aplikací, která už byla naznačena v předchozích dílech, je klasifikace textů. Jedná se o úlohu, jejíž cílem je rozřadit dokumenty do předem daných tříd (např. Kultura, Sport, Počasí, …). Klasický přístup k problém je pomocí reprezentace dokumentů vektory slov při použití nějakého algoritmu strojového učení s učitelem (např. logistická regrese nebo Support Vector Machine). Takové vektory však mají typicky velmi vysoké dimenze a je třeba přistoupit k jejich redukci. Jestliže jsou třídy vhodně definovány, jeví se použití latentních metod pro redukci dimenze jako velmi výhodné.
- Cílení reklamy – reklama je dnes všude kolem nás a pokud má být efektivní, je třeba ji vhodně cílit na zákazníky. Cílením se rozumí nabízení takové reklamy, která je pro zákazníka zajímavá a přínosná. Pokud jde např. o kontextovou reklamu na webových stránkách je nasnadě zobrazovat takovou reklamu, jejíž vektor témat je co nejpodobnější vektoru témat stránky.
- Tematická koherence a schopnost učení se z textu – jedná se o dvě různé úlohy, které ovšem mají mnoho společného. Koherentním (soudržným) textem rozumíme takový text, který plynule přechází od jednoho tématu k druhému a nejsou v něm ostré tematické nebo stylistické skoky. Výrazně nekohorentní text může značit například jeho vytvoření poskládáním cizích textů a jeho detekce tak může pomoci k odhalení plagiátorství. Nekoherentní text lze detekovat porovnáním vektorů témat sousedních odstavců. Pokud je text koherentní, měla by být podobnost jejich vektorů velmi vysoká.
Dalším zajímavým problémem je určení míry schopnosti učení se z textu. Ve článku Using Latent Semantic Analysis to assess knowledge: Some technical considerations autoři popisují využití LSA pro ohodnocení textů, které by mělo odpovídat jejich srozumitelnosti studentům. Hlavní myšlenka spočívá v tom, že by dokument optimálně neměl obsahovat ani příliš málo ani příliš mnoho LSA konceptů (témat).
- Thesaurus a synonymie – vhledem k tomu, že i jednotlivá slova lze považovat za krátké dokumenty, je k nim možné vytvořit vektor témat. Díky tomu lze slova s podobnými vektory shlukovat a automaticky tak vytvořit thesaurus. Nebude se však jednat o synonymii v pravém slova smyslu. Velmi blízké vektory budou mít například všechny barvy nebo dny v týdnu. Dochází k tomu proto, že se tato slova používají stejným způsobem a nelze je tedy jednoduše v prostoru témat rozlišit.
Zajímavější proto může být použití vektorů témat pro identifikaci různých významů. Může nás například zajímat, zda se nezmění význam slova, pokud odebereme diakritiku. Pro příklad, slovo „železo“ na odebrání diakritiky náchylné není a je u něj možné jednoznačně rekonstruovat slovo původní. Na druhou stranu u slova „měď“ už to možné není, neboť „med“ může mít naprosto odlišný význam.
Jiným příkladem využití identifikace různých významů může být detekce sousloví, u kterých neplatí princip kompozicionality (význam celého slovního spojení není dán významem jednotlivých částí). Příkladem může být „vysoká škola“ nebo „kočka domácí“. Pokud tematický vektor celého sousloví nemá předpokládaný směr daný vektory jednotlivých slov, jedná se jedná se s velkou pravděpodobností o nekompozicionální sousloví. Tímto problémem se zabývá např. článek Automatic identification of non-compositional multi-word expressions using latent semantic analysis.
- Doporučování – metody sémantické analýzy lze aplikovat nejen na texty. Zajímavým příkladem je např. doporučování vhodných filmů uživatelům. Alternativou k dokumentům jsou zde uživatelé a ke slovům v dokumentech filmy, které už uživatel označil jako své oblíbené. Pomocí metod sémantické analýzy lze pro každého uživatele vytvořit vektor latentních témat, stejně tak jako nalézt takový vektor pro všechny filmy v databázi. Porovnáváním vektorů uživatelů a filmů lze identifikovat takové filmy, které by se uživateli mohly líbit, protože mají podobné vlastnosti jako filmy, které sám označil jako své oblíbené.
Jiným příkladem doporučování je hledání vhodného recenzenta odborného článku. Dokumentem je zde opět člověk, tentokrát recenzent, a obsahem dokumentu texty všech článků, ke kterým v minulosti psal recenzi. Při rozhodování o přiřazení recenzenta novému článku vybereme takového, jehož vektor témat je nejpodobnější vektoru témat nového článku. Takový systém byl popsán v článku Using Linear Algebra for Intelligent Information Retrieval.
Užitečných aplikací je možné vymyslet mnohem více, ale pro inspiraci by to mělo stačit. Zbývá už jen doporučit vhodné nástroje a knihovny, které práci s tematickými modely usnadní:
- R, Octave, Matlab – pokud se rozhodnete používat pouze LSA, vystačíte si v podstatě s libovolným nástrojem pro numerickou matematiku, který umí řešit Singular Value Decomposition. Samotná implementace LSA je pak už velice snadná.
- Gensim – gensim je knihovna v pythonu, která umožňuje velmi jednoduché použití LSA a LDA, a to dokonce distribuovaně na více strojích.
- Hierarchical Bayes Compiler – pro pokročilejší uživatele mohu doporučit HBC, což je nástroj, kterému předložíte v metajazyce zapsaný pravděpodobnostní model (např. LDA) a on vám vygeneruje zdrojový kód vzorkovače. Jeho výhodou je, že si můžete jednoduše testovat vlastní modely, které jsou třeba jen vzdáleně podobné LDA.
- GibbsLDA++ – jedná se o rychlou implementaci LDA v C++, která využívá Gibbsova vzorkovače.
- Yahoo LDA – implementace LDA od Yahoo, určená pro distribuované počítání LDA modelů nad Apache Hadoop.
Tímto seriál o sémantické analýze textů končí. Pokud máte jakékoliv otázky k tématu, rád je zodpovím. Rád si přečtu i komentáře k seriálu jako celku, abych věděl, zda mám do budoucna počítat s dalším seriálem podobného ražení.


