
Nové kategorie a parametry od července 2026
Po nedávném souhrnu novinek přinášíme přehled nových kategorií, nově založených či upravených parametrů a dalších změn, ke kterým došlo v červnu roku 2026.
Jak jste si již určitě všimli, velice podrobně informujeme na blogu o každé novince, kterou nasadíme do webového rozhraní, abychom vám práci s vaším účtem co nejvíce usnadnili.
Sklik není jen webové rozhraní, které používá aktivně skoro 40 tisíc klientů, ale také spousta technologie pro zpracování inzerátů a následně jejich výdej. Právě pokud jde o technologie, tak byly roky 2012 a 2013 pro Sklik velice plodné. Celý systém se změnil k nepoznání a k lepšímu.
Vývojáři Skliku se museli seznámit s novinkami z úplně jiného technologického světa. Na mnoha místech jsme začali používat distribuované řešení (Hadoop). Udělali jsme také velký pokrok díky preciznější aplikaci matematiky a masivnímu nasazení strojového učení.
V následujících několika odstavcích se pokusíme zrekapitulovat zásadní milníky nejen z minulého roku.
V průběhu roku 2012 jsme velmi pilně pracovali na tom, abychom se seznámili se systémem Hadoop pro první velký projekt Redesign statistik. Původní řešení již nezvládalo zpracovávat tak ohromné množství statistických dat a potřebovali jsme změnu. V tomto roce jsme se dokázali s systémem zcela sžít a z problematické komponenty agregace statistik udělat velice stabilní a neomezeně škalovatelnou továrnu na výrobu statistik v podstatě na cokoliv, co je v systému k dispozici. Zanedbáme-li technologickou vyspělost celého systému, přidaná hodnota z hlediska businessu je v tom, že od nasazení máme po ruce data prakticky ihned a navíc taková, jaká chceme. I když pro uživatele nejsou tato data v rozhraní dostupná, my je máme. Bude ještě nějakou dobu trvat, než je zpřístupníme ve webovém rozhraní třeba formou nové metriky, ale pro nás jsou naprosto zásadní z hlediska dalšího rozvoje systému.
V lednu 2013 přichází první velký zásah do relevance ve vyhledávání za celou dobu existence Skliku. Měníme výpočet míry prokliku (CTR) pro řazení inzerátů. Již nepočítáme a nenormalizujeme CTR, ale přecházíme na tzv. EC (expected clicks).
Tento koncept jsme úspěšně vyzkoušeli nejprve v obsahové síti a to koncem roku 2012, kde se prokázaly jeho kvality. Proto jsme jej ihned na začátku roku 2013 nasadili do vyhledávání. Provozní AB testování a nasazení trvalo měsíc. Troufáme si tvrdit, že postupnou změnu museli ve svých účtech pocítit všichni inzerenti. Ať již kladně, nebo záporně. Každopádně se více zaměřujeme na kvalitu a tento trend bude pokračovat.
Následující grafy ukazují, jak se změnilo CTR inzeratů.

V obsahové síti byl nárůst CTR větší než 100 %
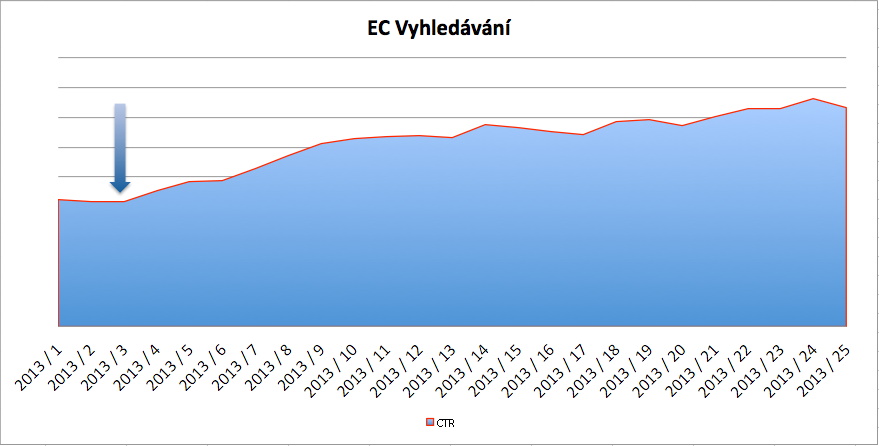
Ve vyhledávání byl nárůst CTR takřka 80 %.
Březen 2013 byl zlomový měsíc z pohledu statistik, a opět si pozorný inzerent mohl všimnout změny. V tomto měsíci jsme zmigrovali statistiky a kompletně je přesunuli do distribuované databáze Hbase. Prakticky to znamenalo migraci dat několika desítek instancí MySQL databáze, ve které byly statistiky uloženy jinam. I ta nejmenší tabulka již byla pro MySQL hodně velká, ani vlastní řešení škálování již nestačilo a v tuto chvíli nutně musela změna technologie přijít.
Cílem redesignu bylo zásadní zrychlení čtení statistik zejména pro velké účty, možnost ukládání dalších metrik a vytváření dalších statistik. Škálování formou přidání dalšího stroje do clusteru bez nutnosti zásahu do databáze je již jen třešničkou na dortu. Migrace na novou technologii dopadla nad očekávání dobře. Dohromady si testování migrace a paralelní běh, kdy jsme sledovali, zda statistiky sedí, vyžádali 2 měsíce pozornosti našich administrátorů a programátorů.
Pro bližší představu s čím se museli naši programátoři a administrátoři vypořádat uvedeme několik čísel:
„Ke každému vydanému inzerátu si musíme pamatovat všechno důležité. Žádná statistika nikdy neexpiruje (pamatujeme si vše do minulosti).“
O klientské statistiky se nyní stará cluster 20 strojů s nakonfigurovanou kapacitou 120 TB a databází HBase.Čtení statistik velkých účtů, které dělalo největší problémy, zejména pak pro klienty, kteří používali API a pro své externí systémy si potřebovali tahat značné množství dat, se zásadně zrychlilo. Vzhledem k tomu, že se jednalo o pro nás naprosto neznámé využití nové technologie, se kterou máme jen napatrné zkušenosti, dá se to považovat za velký úspěch.
V květnu 2013 jsme poprvé začali pracovat na retargetingu. I když to nemusí být na první pohled patrné, jedná se o poměrně komplikovaný systém, který musí svou podstatou (cílením na uživatele) pěkně zapadnout mezi ostatní komponenty Skliku. Celý projekt se skládal z několika částí a to z úpravy webového rozhraní, počítání statistik, úpravy výdeje, počítání zpětné vazby. Začlenění retargetingového inzerátu mezi inzeráty kontextu znamenalo provést zásadní změny ve výdeji kontextových inzerátů. Tato fáze, dohromady s přípravou webového rozhraní zabrala podstatnou část při implementaci.
„První inzerát přes retargeting se vydal 20.11.2013.“
Retargeting byl spuštěn v neveřejném beta testu, kde jsme ověřovali jeho kvality, dříve než jej dáme volně k dispozici. Testování probíhalo s velkými klienty a trvalo asi 2 měsíce a již v průběhu testu jsme měli pokrytí retargetingem v obsahu okolo 15 %. Nyní je již tento typ cílení dostupný pro všechny klienty a pokud se chcete dozvědět o retargetingu více stačí si přečíst tento článek.
Květen 2013 byl měsíc, kdy jsme začali veřejně testovat nové počítání relevance postavené na rozhodovacích stromech. Celý projekt “lesní relevance” trval asi 6 měsíců a měl za úkol lépe řešit relevanci inzerátů na dotaz. V tomto projektu jsme si poprvé v provozní praxi vyzkoušeli strojové učení, které mělo na relevanci velice pozitivní vliv.
I když si jsme vědomi, že na spousty dotazů ještě zdaleka neumíme najít ty nejlepší inzeráty, měl tento projekt jednoznačně kladný dopad na CTR. V následujících letních měsících jsme systém důkladně sledovali a postupně upravovali klíčové nastavení, kdy jsme nakonec v září dospěli k zásadnímu zjednodušení řazení inzerátů ve vyhledávání podle čistého součinu CTR x relevance x cena. Na nás
ledujícím grafu je vidět CTR ve vyhledávání, které má opět stoupající trend. Relevance zůstává nejen z pohledu našeho výzkumného oddělení nekonečným projektem, a tak na ní pracujeme stále.
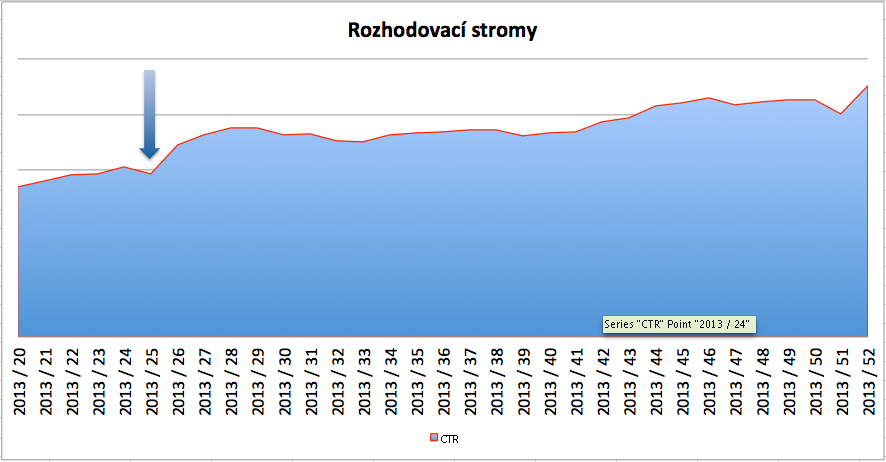
Nárůst CTR ve vyhledávání.
Další poměrně rozsáhlý projekt, který začal již v roce 2012 a jehož cílem jsou převážně zásahy do architektury, je rozdělení hlavní databáze. Asi není úplným tajemstvím, že Seznam jako úložiště dat svých aplikací používá MySQL a stejně tak je tomu i v případě Skliku. S tím, jak nám do systému přibývají další a další data, je potřeba tato data nějakým způsobem škálovat. Hlavní databáze Skliku (databáze ve které jsou uloženy klientská data, kampaně, sestavy) nebyla navržena tak, aby byla horizontálně škálovatelná.
Opět pro představu uvedu několik čísel:
„Vypadá to, že všechny velké eshopy mají u nás svá data. Co to je v porovnání třeba s registrem automobilů…?“
Výdejové komponenty již byly designovány před delší dobou a nyní přišla na řadu databáze. Celý projekt trval více než rok, v průběhu kterého jsme museli upravit všechny komponenty závislé na hlavní databázi a přesunu všech dat do databáze nové naškálované struktury. Poslední účet jsme přesunuli první týden v lednu, a pokud jste si ničeho zvláštního nevšimli, jen se vám zdá, že je rozhraní mírně rychlejší, tak je vše v naprostém pořádku.
Nebudeme prozrazovat, co konkrétně chystáme v Skliku spustit v letošním roce, nechte se překvapit. I tento rok se budeme věnovat všem důležitým částem systému. Přibudou nové funkce do webového rozhraní, přidáme další možností cílení reklamy a opět se zaměříme na “relevanci” reklamy tak, abychom našim klientů přinesli za jejich investované peníze co nejvíce zákazníků.
Za celý tým Skliku, Zdeněk Philipp
Po nedávném souhrnu novinek přinášíme přehled nových kategorií, nově založených či upravených parametrů a dalších změn, ke kterým došlo v červnu roku 2026.

V květnu jsme představili nové měření SEM (Seznam Event Measurement), které přináší přesnější měření konverzí i nové možnosti retargetingu. Pokud už máte implementaci otestovanou, můžete nyní svůj účet Skliku na SEM přepnout.

Vlastní zákaznická data patří mezi nejcennější komodity v online marketingu. Přesto je řada inzerentů stále nevyužívá naplno. Radek Svoboda ve své přednášce ukazuje, jak z vlastních dat vytěžit maximum, zjednodušit si práci díky automatizaci a oslovovat zákazníky relevantněji.