Ve Vyhledávání si klademe za cíl uspokojit relevantními výsledky co největší množství našich uživatelů. K tomu je zapotřebí souhry celé řady okolností, např. potřebujeme mít relevantní dokument v indexu a správně vyhodnotit jeho relevanci vůči pochopenému dotazu.
Právě v rámci pochopení dotazu, které stojí na počátku celého procesu vyhledávání, se v první fázi snažíme v dotazech opravit případné překlepy. Pokud se nám toto nepodaří, skončí celé vyhledávání zpravidla nezdarem. Abychom tyto případy minimalizovali, věnovali jsme v uplynulých měsících pozornost vylepšování nástrojů, které opravu překlepů provádějí. Ty jsou celkem dva a fungují následujícím způsobem:
Na chybně napsaný dotaz uživateli můžeme nabídnout návrh opravy. Pokud na něj klikne, objeví se mu výsledky pro opravený dotaz. Druhou možností je okamžité zahledání opravy bez nutnosti další interakce s uživatelem. Provádíme jej u dotazů, u nichž jsme si návrhem opravy dostatečně jistí díky zpětné vazbě od uživatelů. Ti tak rovnou dostávají výsledky pro opravený dotaz.
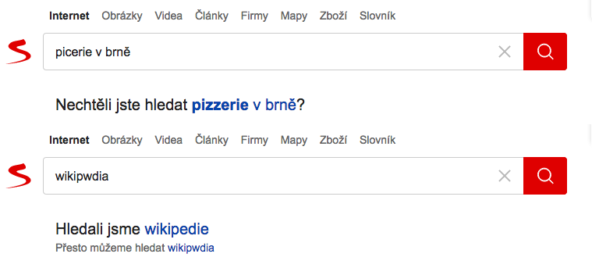
Na horním obrázku se nachází návrh na opravu. Uživatel na něj musí kliknout, aby dostal výsledky pro opravený dotaz. Na dolním obrázku se nachází ukázka opravy, která se rovnou zahledává.
Nutným předpokladem pro úspěšnost obou nástrojů je skutečnost, že dotazy obsahující chybu umíme účinně poznat a opravit. Za cíl našeho snažení jsme si stanovili zvýšit počet opravovaných dotazů. Jinými slovy – chceme uživatelům zobrazovat správný návrh na opravu u co největšího množství chybných dotazů.
Každý zobrazený návrh na opravu je výsledkem několikastupňového procesu. Na začátku pro daný dotaz vygenerujeme poměrně velké množství různých variant na jeho opravu. S pomocí různorodých signálů vybereme následně menší počet kandidátů a přiřadíme jim skóre, které říká, jak dobrý daný kandidát pravděpodobně je. Opět na základě signálů několik nejlepších kandidátů porovnáme mezi sebou včetně možnosti dotaz neopravovat. Pokud existuje kandidát hodnocený lépe než původní dotaz, pak jej vydáváme jako návrh na opravu (popř. ten nejlepší z několika kandidátů). Pro splnění našeho cíle jsme potřebovali zlepšit nejen způsob, jakým kandidáty vybíráme a hodnotíme, ale také data, na jejichž základě tato vyhodnocení provádíme.
V prvním kroku jsme se zaměřili na konzistentní a aktualizované zpracování dat, na nichž učíme model správně vybírat a hodnotit kandidáty na opravu. Zjednodušeně – ke značnému množství dotazů stanovíme, jak by měly být správně opraveny, a doplníme je statistickými údaji. Část dat je připravována ručně. Anotátoři projdou velké množství dotazů a opraví ty, které obsahují chyby. Další část dat vyrábíme automaticky. Sbíráme statistiky o tom, jak často jsou dotazy hledané, jak je uživatelé reformulují, a další data. Pro automaticky generovaná data jsme zajistili, aby se sama pravidelně obnovovala a odpovídala tak nejnovějším trendům ve vyhledávání.
Kolik překlepů byste dokázali odhalit?
Další část práce se vztahovala k vylepšení samotného modelu. Zrevidovali jsme současný stav a také signály, s jejichž pomocí se rozhoduje. Zbavili jsme se těch již zastaralých a opravili nalezené nesrovnalosti. Dále jsme se rozhodli použít k vyhodnocování oprav nový algoritmus. Otestovali jsme několik verzí a původní algoritmus jsme nahradili tou, která podávala nejlepší výsledky. Přineslo nám to zejména výrazné zrychlení učení modelu. Díky tomu jej můžeme častěji přeučovat na aktualizovaných datech. Model se pak lépe dokáže adaptovat na to, co zrovna v daném období uživatelé hledají a v čem chybují.
Díky těmto úpravám jsme začali opravovat o necelou polovinu více dotazů než doposud. Ruku v ruce s tím šlo i zvýšení počtu rovnou zahledávaných oprav, jelikož k nim přešla část nových návrhů.
Oprava překlepů je pro nás natolik důležité téma, že v jejím rozvoji chceme dále pokračovat. Dalším krokem bude revize a následné zdokonalení využití uživatelské zpětné vazby.


