Studenti středních a vysokých škol svými hlasy opět rozhodli, že je Seznam.cz TOP zaměstnavatelem v oblasti IT. Z prvenství máme obrovskou radost a vnímáme ho jako signál, že způsob, jakým v Seznamu pracujeme, má smysl i mimo naše zdi. Věříme, že za tímto úspěchem stojí každodenní spolupráce, důvěra a hlavně lidé, kteří Seznam tvoří. A právě jim patří velký dík. Pokud vás zajímá, jak to u nás funguje doopravdy, podívejte se na naše volné pozice. A když vás nějaká zaujme, rádi se s vámi poznáme.
Provoz Seznamu očima network adminů
17. prosince 2018
V předchozím článku psal Vlastimil Pečínka o technickém oddělení a provozu Seznam.cz. Dnes se podíváme trochu blíže na oddělení network administrátorů a na to, jaké výzvy tu řešíme.
Trocha historie
Seznam začínal jako správná garážovka na počítači vrčícím v obýváku táty Iva Lukačoviče a na vytáčeném modemovém připojení.
Od přestěhování do datového centra se mnohé změnilo. Prioritou se stala stabilita prostředí a škálování výkonu. V roce 2006 jsme na vlastní kůži zjistili, že riziko výpadku celého datacentra opravdu existuje (i když je provozovatelem garantovaná velmi vysoká dostupnost). První zásadní rozhodnutí bylo zřejmé – datacentra budou dvě. Zpočátku se počítalo jen s jedním záložním, ale proč servery nevyužít, když už tam jsou a jen čekají na výpadek.
Nyní každé datacentrum obsluhuje 50 % provozu a v případě výpadku musí to druhé obsloužit vše. Pojďme ale trochu více do hloubky.
Jak to funguje
Základní koncept sítě v datacentrech nepřekvapí – servery zapojené do switchů, switche do routerů a z routerů ven do internetu. V rozsáhlých datacentrech se dostanete do stavu, kdy musíte škálovat jak do šířky (tj. když přidáváte servery, přidáváte switche), tak do výšky (s rostoucím počtem serverů a aplikací roste datový tok, proto zvyšujete výkon a propustnost switchů, routerů, páteřních tras nebo třeba i internetového připojení). Vše navrhujete tak, aby výpadek či plánovaná odstávka jakéhokoliv zařízení neodstavila celé datové centrum. Proto je třeba mít uvnitř vše dvakrát.
Bohužel tady platí dvojnásob, že síť je tak stabilní, jak stabilní je software uvnitř switchů/routerů. Zkuste se poptat síťařů jakékoliv větší firmy a ti vám jistě vysypou z rukávu neuvěřitelné tragikomické historky. K tomu si přisaďte, že každý výrobce se snaží mít vždy několik „háčků“, které vás mají udržet jen u toho jednoho správného výrobce, protože jedině tak vám to bude vše dohromady fungovat. Narážím zejména na proprietární protokoly či nekompatibility mezi výrobci. Na druhou stranu vše stojí nemalé peníze. Nákupem zařízení to rozhodně nekončí.
Abyste mohli aktualizovat bezpečnostní záplaty, musíte si platit roční supporty, což z hlediska životnosti zařízení je zpravidla v součtu vyšší částka než částka pořizovací.

Jak z toho ven
Jednoduchá cesta neexistuje, a tak jsme v Seznamu před několika lety vsadili na několik změn:
- Neakceptujeme vendor-lock technologie
Je velmi lákavé použít technologie, které mají vyřešit spousty problémů. Ale v detailu je skrytý ďábel, který vám právě podává ruku. Přitom stačí málo – zkuste si při každé úpravě architektury otestovat zařízení od více výrobců dohromady.
- Na prvním místě je stabilita a rychlost sítě
Všechna rozhodování musí být s cílem zajištění stability a rychlosti sítě. Není nic horšího, než když se síťové boxy samy rebootují bez zjevné chyby a vezmou s sebou nemalé množství serverů. A po měsících hledání příčin zjistíte, že byla chyba u výrobce.
- Každý box sám za sebe
Pokud to je možné, každý síťový box by měl mít svoji rozhodovací funkci. Jinak vám může odpadnout velký segment sítě díky několika zařízením, která jsou virtuálně spřažena do jednoho a zrovinka si vyberou tu svou chvilku slávy.
- Po síti v datacentrech budeme jen routovat
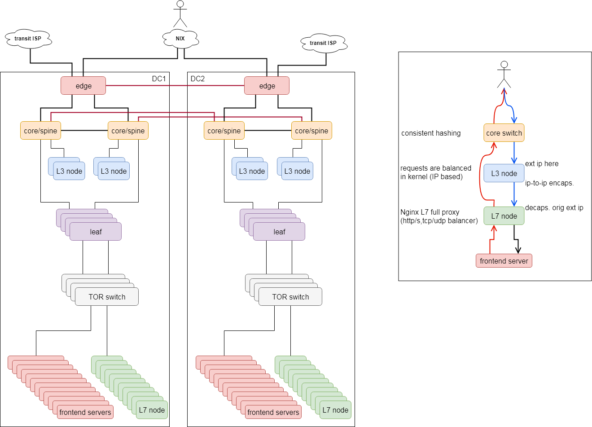
Pokud je síť v datacentru postavena tak, že máte více cest od zdroje k cíli, při rozhodování kudy a kam rámec poslat se běžně volí přepínaná síť na L2 protokolech. S rostoucí šířkou datacentra a nasazováním velikých aplikačních clusterů začnete řešit, jak zkrátit trasy a jak minimalizovat broadcastové domény, a tím zbytečný režijní traffic. L2 síť dává smysl na spoustě míst, ale nakonec jsme se rozhodli, že v datacentru budeme routovat na L3 vrstvě. Necháme tak veškeré rozhodování o správné trase na BGP protokolu. V zásadě jsme si v datacentru postavili malý internet, který je jako ten velký rozsegmentován na jednotlivé autonomní systémy s vlastními IP rozsahy. Z pohledu serverů je výchozí brána vždy na nejbližším TOR (top-of-rack) switchi, který paket dále už jen routuje dle trasy k autonomnímu systému IP adresy cíle. Třešnička na dortu je, že můžete používat nástroje jako traceroute, díky čemuž vidíte do celé trasy sítě přímo ze serveru.
- Jsme nablízku open-source projektům
Stavět vlastní servery už umíme, tak proč si nepostavit i vlastní síťové boxy? Ano, i s touto myšlenkou si pohráváme. Prozatím jsme u testování OpenSwitch/OpenNetworkLinux variant –nakoupíme HW a nahrajeme si vlastní operační systém. Bude to ještě pár let trvat, ale chceme být u toho.
- Přejdeme od HW balancerů k distribuovaným balancerům postavených na open-source
Je zvláštní, jak se situace za posledních 15 let několikrát opakuje. Kolem roku 2006, kdy jsme používali HW balancery, jsme po pár peripetiích přešli na IPVS (L4 balancing v kernelu) právě z důvodu, že na linuxových serverech jsme schopni elegantně škálovat. S narůstajícím objemem dat jsme se po několika letech vrátili zpět k HW boxům, u kterých jsme téměř 10 let. Ale poslední 2 roky s různou intenzitou pracujeme na vlastním distribuovaném a lehce škálovatelném balanceru postaveném ve dvou úrovních. První balancuje pouze příchozí requesty (IPVS v kernelu) na vrstvu druhou. Tam sedí armáda Nginx serverů, které balancují na cílové servery. Okolo toho je několik servisních aplikací například API pro konfiguraci a stavové informace. Nutno dodat, že tento projekt je v největších obrátkách právě nyní, protože se jedná o zásadní stavební kámen celého SCIF projektu.
Závěrem snad jen pár těžce nabytých rad, které sice zní jako klišé, ale v dlouhodobém horizontu fungují. Zejména Murphyho „co se může pokazit, to se (jednou) pokazí“ platí na síti bezezbytku. O to svědomitější v rozhodování musíte být. Je to jako byste stavěli hrad z karet – jak stabilní základy uděláte, takový hrad budete mít.

Martin Doleček, Manažer provozního oddělení

