Znáte strukturovaná data? Víte, co to vlastně je, co umí a proč byste je měli chtít využívat? Od toho jsme tu my a náš nový seriál, který vám o strukturovaných datech řekne vše, co jste třeba ještě nevěděli. V prvním dílu vám představíme typy těchto dat a jejich využití.
Co vlastně strukturovaná data jsou? Jde o metadata, která pomáhají pochopit význam informací na nějaké webové stránce. Když se na webovou stránku podívá člověk, většinou hned ví, o čem stránka je a jaký význam informace na ní mají. Pokud se ale na stránku podívá stroj (například náš Seznambot), informace o významu mu často unikají. Díky strukturovaným datům mohou i stroje pochopit význam informací a tyto informace se poté mohou dále využít.
Typy strukturovaných dat
Existuje několik typů strukturovaných dat, které se od sebe liší zejména způsobem, jakým se zapisují do zdrojového kódu stránky. Dva základní typy jsou schema.org a Open Graph. S těmito dvěma typy pracujeme i u nás v Seznamu. Bohužel momentálně neexistuje žádný vyloženě standardizovaný přístup ke strukturovaným datům, což vede k úskalím v rámci jejich zpracování. Oba typy sice poskytují šablony, dle kterých se strukturovaná data mají správně vyplňovat, ale už neexistuje žádná jistota, že je administrátoři webu opravdu správně vyplní.
Schema.org
Schema.org je kolaborativní komunitní projekt, který má za cíl vytvářet, standardizovat a udržovat schémata pro vyplňování strukturovaných dat. Velké množství stránek na internetu se řídí právě tímto standardem. Na stránce projektu lze najít konkrétní schémata pro konkrétní potřebu. Například, když chceme popsat produkt, událost, knihu nebo film.
Příklad:
Jsem administrátor webové stránky o filmu Rocky. Na stránce mám informace o tom, kdy byl film natočen, kdo tam hrál, kdo film režíroval, do jakého žánru film spadá atd. Tyto informace potřebuji nějakým způsobem strukturovat, aby byly čitelné a srozumitelné i pro stroje.
Podívám se na stránky schema.org, jestli existuje nějaké konkrétní schéma pro film (Movie).
Tento standard byl poprvé zaveden Facebookem v roce 2010. Vyplněním OG tagů se stránka zapojí do „sociálního grafu internetu”. Standard nabízí daleko méně možností než schema.org. Ve Vyhledávání ho používáme zejména pro stahování obrázkových náhledů pro produkty, články či videa.
Příklad:
Jsem administrátor webové stránky o filmu Rocky. Na stránce mám jméno filmu a jeho popis. Tyto informace potřebuji nějakým způsobem strukturovat, aby byly čitelné a srozumitelné i pro stroje.
Podívám se na stránky Open Graph, zda existuje nějaké schéma pro film (Movie).
Do stránky přidám dle standardu OG kus zdrojového kódu, který bude Rockyho popisovat:
<meta property="og:description" content="A small-time boxer gets a supremely rare chance to fight a heavyweight champion...“/>
Jak je vidět z příkladů, Open Graph disponuje daleko menším počtem možností popisu filmu, než schema.org. Navíc lze přes Open Graph definovat jen jeden typ, zatímco jedna stránka může obsahovat více schema.org struktur.
Využití strukturovaných dat ve Vyhledávání
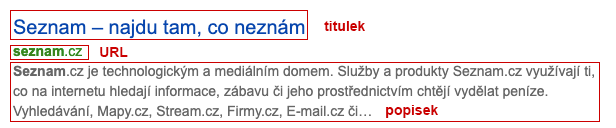
Strukturovaná data využíváme momentálně hlavně při tvorbě tzv. rozšířených snippetů. Snippet je krátký úryvek ze stránky, který jí reprezentuje ve výsledcích vyhledávání.
Klasický snippet má tyto části:
Titulek
URL
Popisek
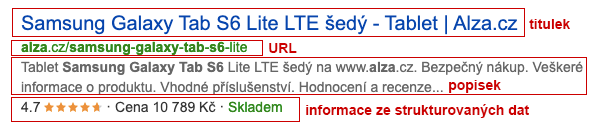
Rozšířený snippet má tyto části:
Titulek
URL
Popisek
Informace ze strukturovaných dat
Ve Vyhledávání aktuálně rozlišujeme následující typy rozšířených snippetů:
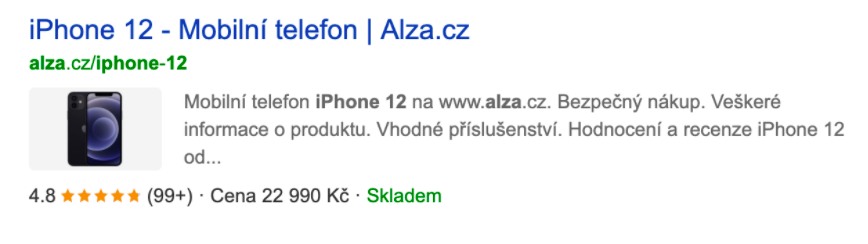
Produktové – rozšířené o obrázek, cenu, hodnocení, skladovost, hodnocení e-shopu nebo jejich libovolnou kombinaci.
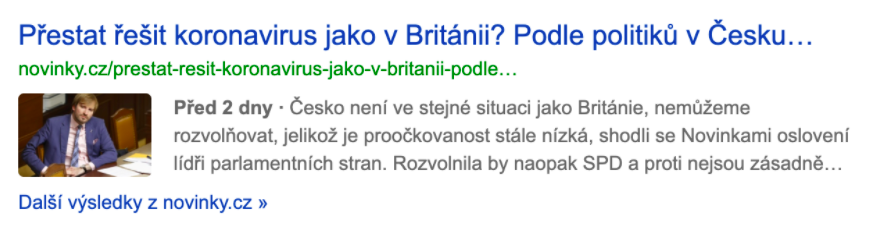
Článkové – rozšířené o datum publikace a autora
Videa – rozšířené o datum publikace, autora a počet shlédnutí
Chcete vědět víc? Využijte tlačítka níže a přejděte na podrobnější články pro jednotlivé druhy snippetů. Dozvíte se mimo jiné, jak strukturovaná data správně vyplnit, aby se v našich snippetech zobrazovala.
Uživatelé v Česku na portálu Sauto.cz nejčastěji vyhledávají automobily spalující benzín*. Současná situace na trhu s palivy ale mnoho lidí, podle dat Seznam.cz Vyhledávání, podněcuje k většímu zájmu o elektroauta. Roste také počet dotazů na ceny benzínu, zejména na čerpacích stanicích Ono. Na Zboží.cz mají lidé větší zájem o kanystry, většinou o ty o objemu 20 litrů. Podíváme-li …
Česká internetová jednička tradičně zveřejnila svoje skokany vyhledávání – výrazy, jejichž hledanost ve srovnání s předchozím rokem vyrostla nejvíce. Mezi častěji zadané dotazy patřily ty na filmovou a seriálovou tvorbu. Konkrétně této kategorii loni kralovala česko-slovenská komedie s názvem Villa Lucia. Na čelní místo žebříčku více hledaných výrazů týkajících se volnočasových aktivit se probojovalo Námořní muzeum …
Page Quality je jedním z nejdůležitějších faktorů, které rozhodují o viditelnosti vašeho webu ve vyhledávání. Nejde jen o technickou metodu hodnocení, ale o souhrn principů, které určují, jak kvalitní, důvěryhodná a uživatelsky přívětivá vaše stránka skutečně je. Zjistěte, co vše Page Quality ovlivňuje a jak můžete její úroveň zvýšit, abyste posílili pozice svého webu v SERPu i důvěru uživatelů.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.