Provozujete stránku se články a chtěli byste, aby se o nich ve výsledcích vyhledávání zobrazovaly podrobnější informace? Ano? Pak stačí využít strukturovaná data. Jestliže nevíte, co to vlastně je, co umí a proč byste je měli chtít využívat, jsme tu my a náš čtyřdílný seriál, který vám o strukturovaných datech řekne vše, co jste třeba ještě nevěděli.
V prvním díle jsme vám představili typy těchto dat a jejich využití. Ve druhém díle jsme se věnovali produktovým snippetům. Ve třetím díle jsme se podívali na snippety k videím. V této části se více dozvíte o tom, jak za pomoci strukturovaných dat rozšiřujeme snippety ke článkům.
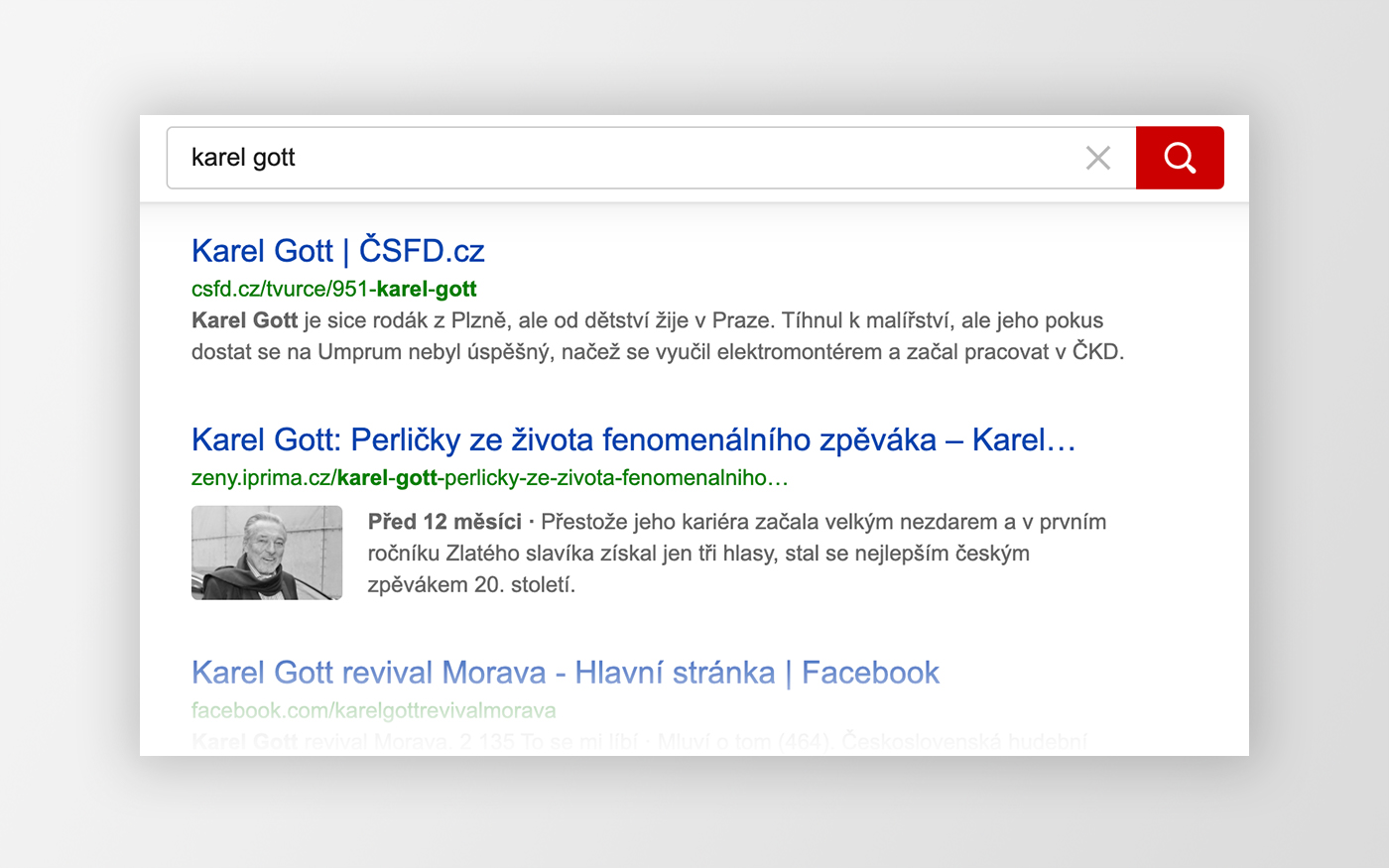
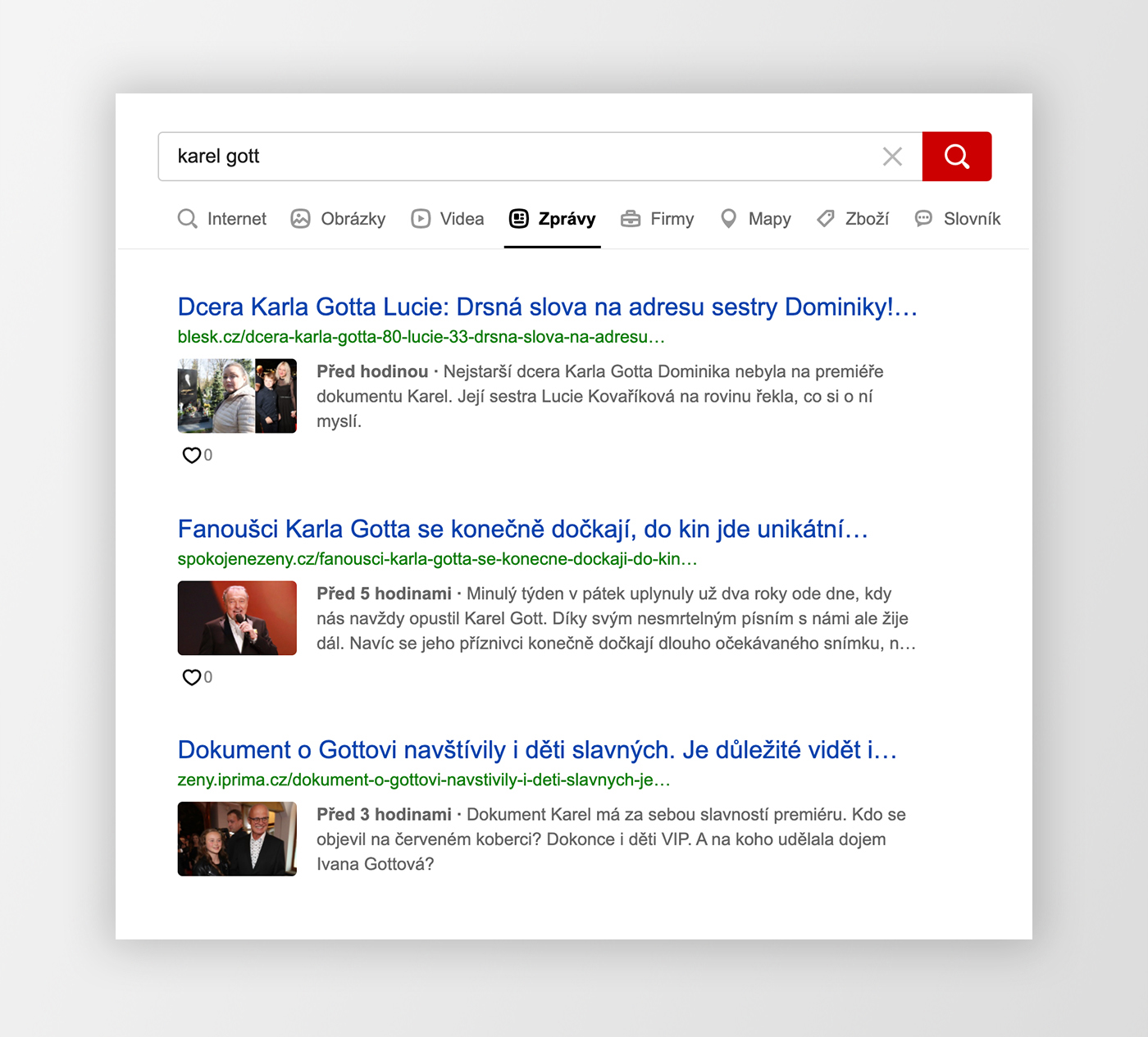
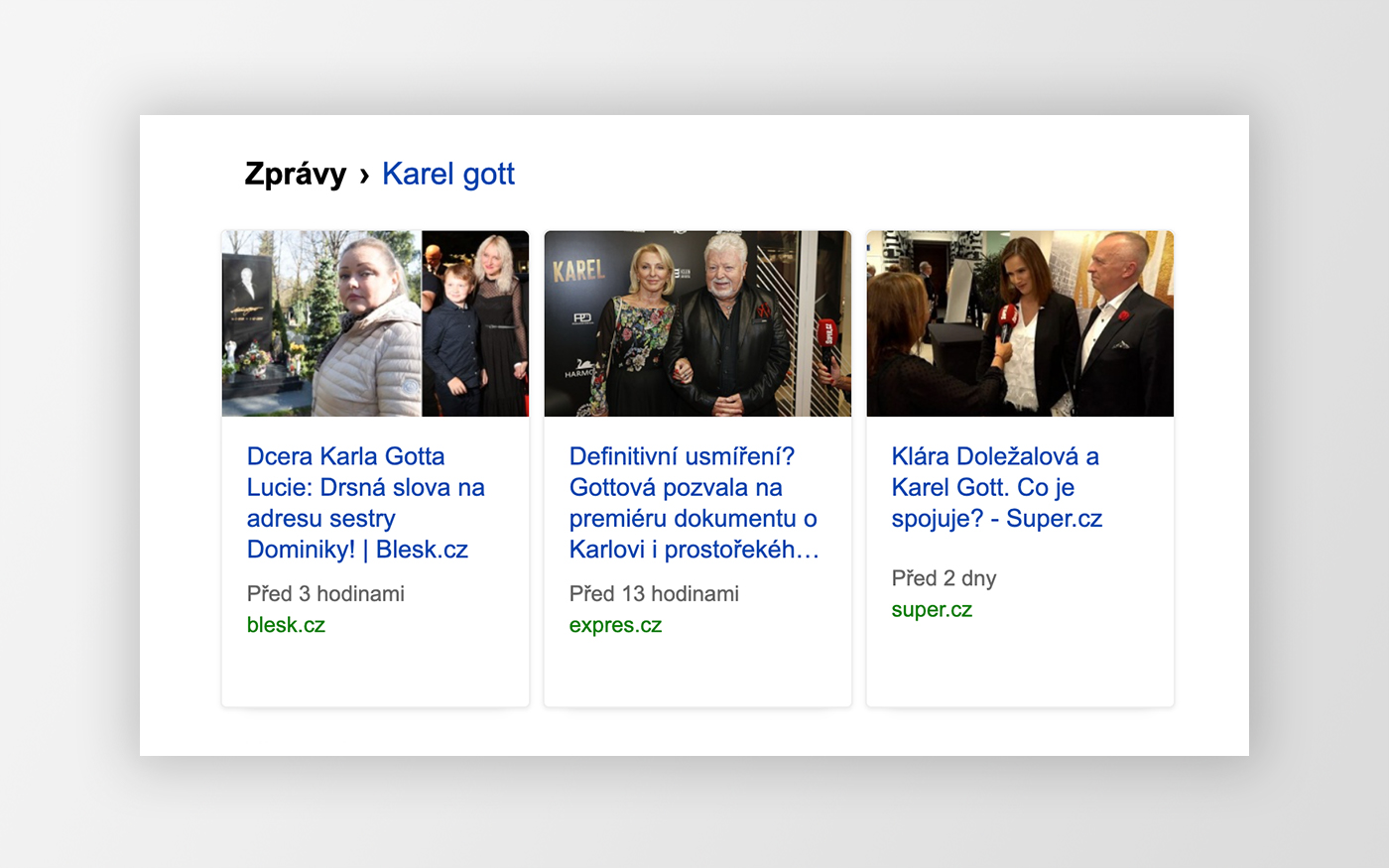
Článkové snippety ve výsledcích přirozeného vyhledávání.Článkové snippety ve výsledcích speciálního článkového (zpravodajského) vyhledávání.Článkové snippety ve speciálním článkovém hintu.
Jak získáváme strukturovaná data pro články?
Strukturovaná data pro zmíněné parametry parsujeme přímo ze zdrojového kódu konkrétní stránky. Většinu jich získáváme z anotací typu schema.org. Pokud v anotacích typu schema.org něco chybí, zkoušíme informace doplnit z anotací typu Open Graph. O těchto dvou typech strukturovaných dat jsme psali v prvním díle této série.
Jak správně vyplnit strukturovaná data?
Aby se v našem vyhledávání strukturovaná data zobrazila, je potřeba je správně vyplnit. V ukázce kódu, který můžete přidat do zdrojového kódu své stránky, vidíte, jak lze nadefinovat parametry článku. U detailu každého parametru najdete informace o tom, v jakém formátu by měl být.
Ukázka schema.org
Schéma ke článkům rozlišuje několik jejich podtypů. Klasický novinový článek například odpovídá podtypu schema.org/NewsArticle. Doporučujeme použít takový podtyp, který nejlépe odpovídá obsahu. Pokud podtyp není jasný, použijte obecný schema.org/Article.
Při zpracování strukturovaných dat ke článkům dáváme přednost schema.org. Doporučujeme proto použít anotace tohoto typu.
Jak otestovat, že jste strukturovaná data vyplnili správně?
Pokud jsou strukturovaná data správně vyplněna, časem se zobrazí v našich video snippetech. Správnou implementaci si můžete zkontrolovat hned, přes https://search.google.com/test/rich-results. Zadáte URL své stránky a spustíte analýzu. Pokud jste data správně vyplnili, bude sekce Articles u sebe mít zelenou „fajfku”.
V případě, že narazíte na jakékoliv problémy se strukturovanými daty ve video snippetech, můžete nám je oznámit pomocí tlačítka Zpětná vazba přímo ve výsledcích vyhledávání nebo zaslat na vyhledavani@firma.seznam.cz.
V minulém příspěvku najdete užitečnou sekci o případných problémech s formátem dat, která se vám jistě bude hodit i u článků.
Na co ještě můžete ve článkových snippetech narazit?
Autor článku
Ze strukturovaných dat dále parsujeme jméno autora článku. Momentálně tuto informaci přímo nevyužíváme. Zkoumáme použitelnost dat. Pokud však budete strukturovaná data vyplňovat, můžete již tuto informaci zahrnout. Použít můžete anotaci typu schema.org.
Doba čtení článku
Novinka, kterou chystáme nasadit během následujícího kvartálu, je odhad doby čtení článku. Jedná se o první parametr ve snippetech, který je námi počítaný a nepochází přímo ze strukturovaných dat. Počítáme ho v našem SeznamBotu podle vzorečku: (počet slov * 60) / (rychlost čtení). Věříme, že uvedením tohoto údaje uživateli dodáme užitečnou informaci navíc, která pro něj bude přínosem.
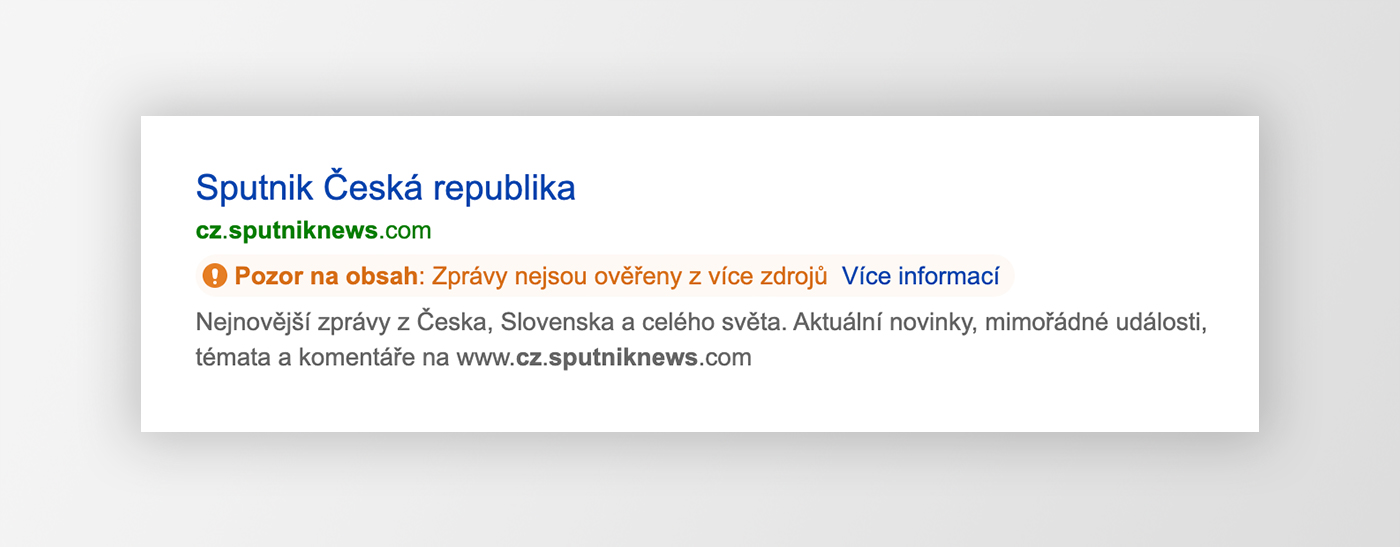
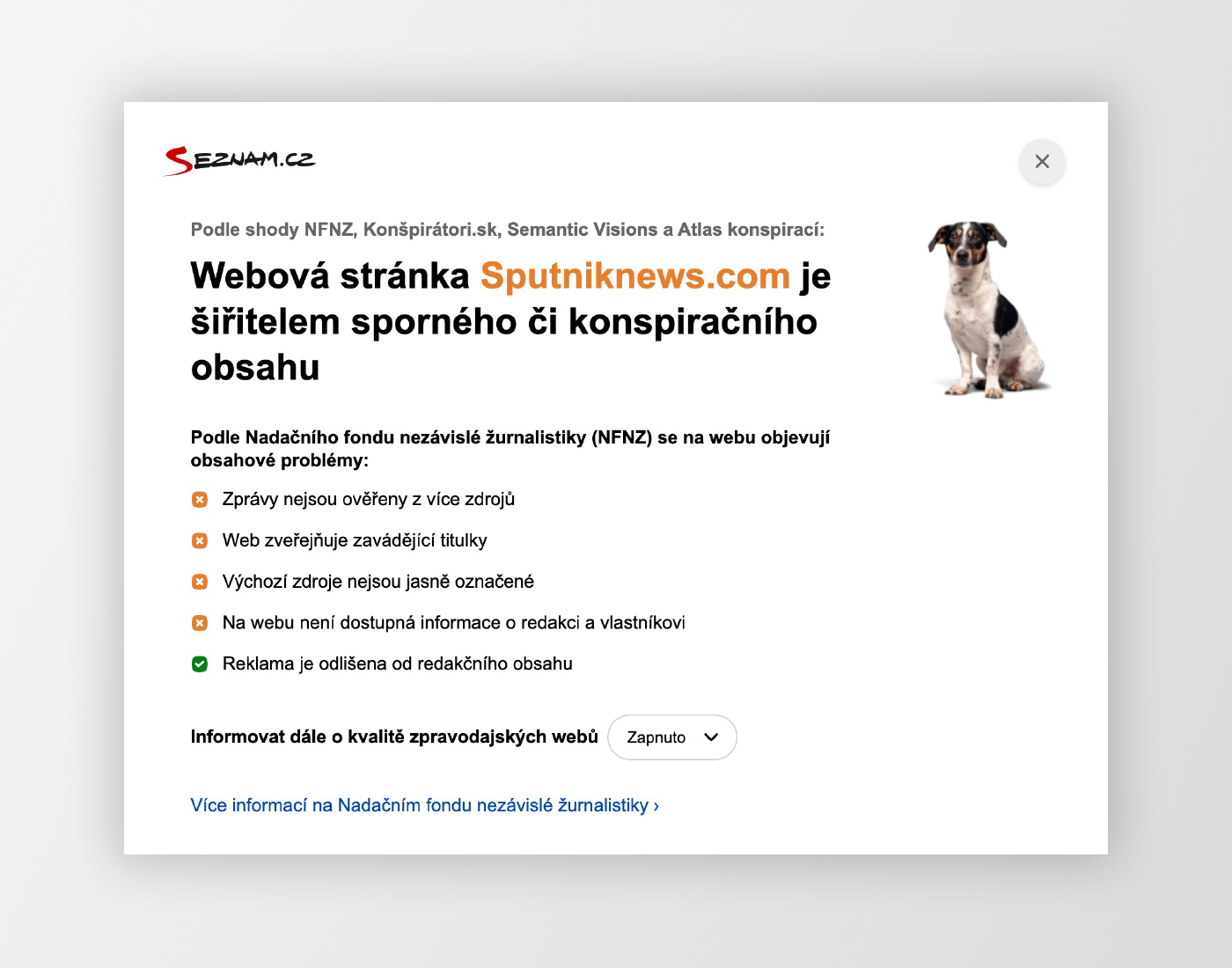
Indikátor fake news
Ukázka snippetu s indikátorem fake news.Ukázka vysvětlení, proč byl zobrazen indikátor fake news.
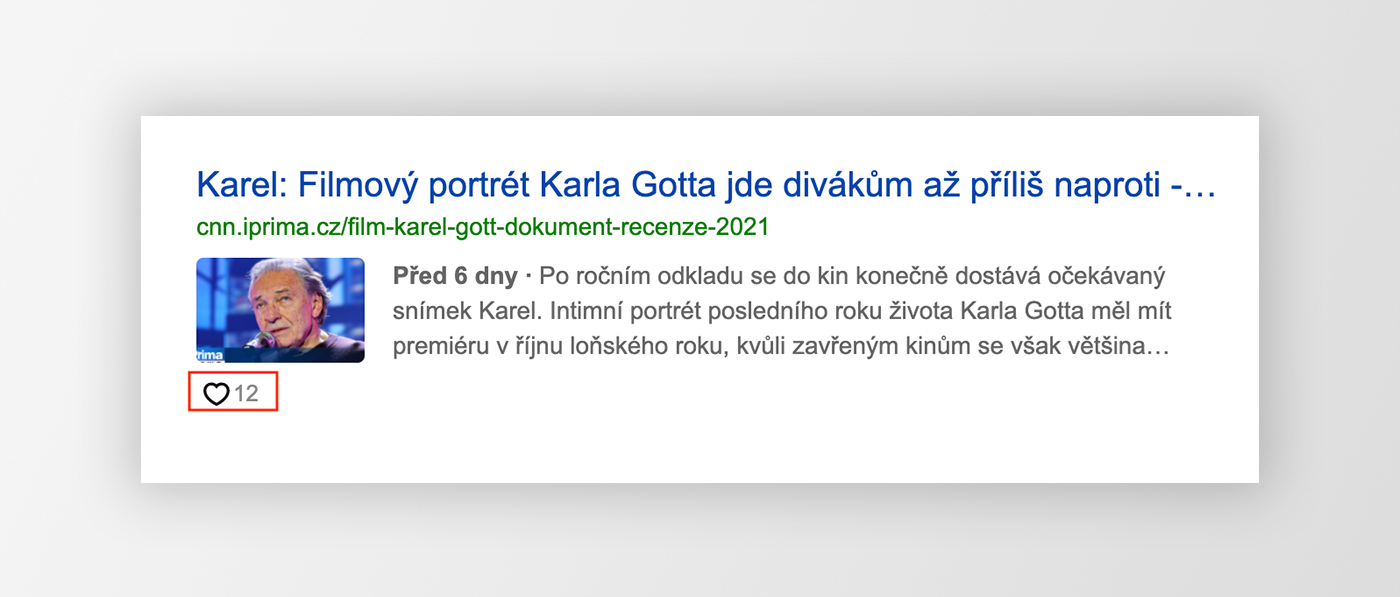
Další dvě novinky. Indikátor počtu lajků je již nasazen. Indikátor počtu komentářů v diskuzi se připravuje. Zdrojem informací nejsou strukturovaná data, ale naše interní databáze.
A je na čase se rozloučit. Tímto dílem uzavíráme sérii článků o využití strukturovaných dat v našich snippetech. Doufáme, že se vám články líbily a byly pro vás přínosem. Pokud byste měli k tématu jakékoliv dotazy nebo nám chtěli dát zpětnou vazbu, neváhejte nás kontaktovat na vyhledavani@firma.seznam.cz. Již teď pro vás připravujeme další zajímavé příspěvky týkající se práce se snippety u nás v Seznamu!
Uživatelé v Česku na portálu Sauto.cz nejčastěji vyhledávají automobily spalující benzín*. Současná situace na trhu s palivy ale mnoho lidí, podle dat Seznam.cz Vyhledávání, podněcuje k většímu zájmu o elektroauta. Roste také počet dotazů na ceny benzínu, zejména na čerpacích stanicích Ono. Na Zboží.cz mají lidé větší zájem o kanystry, většinou o ty o objemu 20 litrů. Podíváme-li …
Česká internetová jednička tradičně zveřejnila svoje skokany vyhledávání – výrazy, jejichž hledanost ve srovnání s předchozím rokem vyrostla nejvíce. Mezi častěji zadané dotazy patřily ty na filmovou a seriálovou tvorbu. Konkrétně této kategorii loni kralovala česko-slovenská komedie s názvem Villa Lucia. Na čelní místo žebříčku více hledaných výrazů týkajících se volnočasových aktivit se probojovalo Námořní muzeum …
Page Quality je jedním z nejdůležitějších faktorů, které rozhodují o viditelnosti vašeho webu ve vyhledávání. Nejde jen o technickou metodu hodnocení, ale o souhrn principů, které určují, jak kvalitní, důvěryhodná a uživatelsky přívětivá vaše stránka skutečně je. Zjistěte, co vše Page Quality ovlivňuje a jak můžete její úroveň zvýšit, abyste posílili pozice svého webu v SERPu i důvěru uživatelů.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.