Máte pod svou správou stránky, které obsahují otázky a odpovědi? Líbilo by se vám, kdyby se tyto otázky a odpovědi zobrazovaly přímo ve výsledcích vyhledávání? Stačí využít strukturovaná data. Co strukturovaná data jsou a jak je na svých stránkách pro tento účel využít, se dočtete v našem dalším článku ze série o snippetech.
Právě jste začali číst již devátý díl naší série o strukturovaných datech a jejich využití ve Vyhledávání. V prvním dílu série jsme vám obecně představili typy strukturovaných dat. V následujících dílech jsme se blíže podívali na strukturovaná data ve snippetech k produktům, videím, článkům, receptům, eventům, diskuzním vláknům a filmům/seriálům.
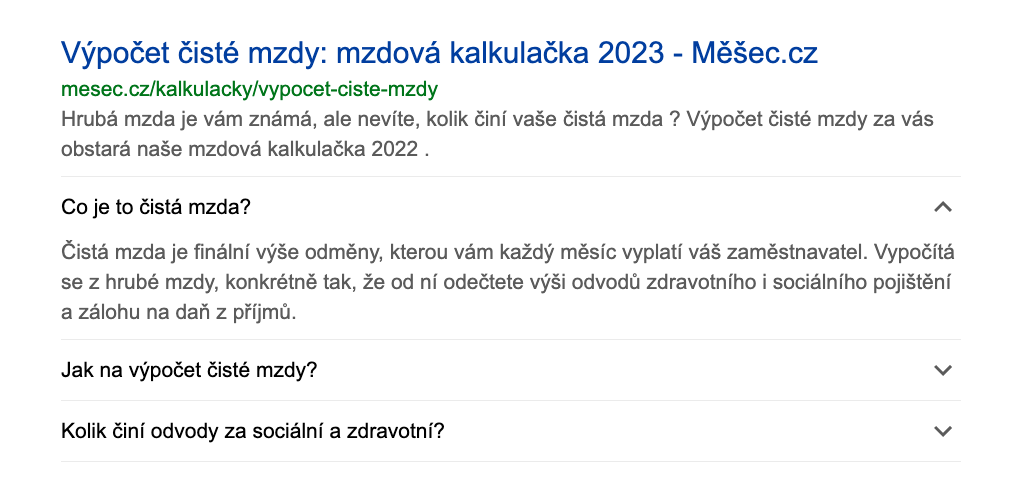
Jak rozšiřujeme snippety k FAQ stránkám?
Snippety k FAQ stránkám zobrazujeme ve výsledcích přirozeného hledání. Zaměřujeme se na dokumenty, které se snaží poradit s nějakým problémem. FAQ data, která slouží jako promo nebo reklama dokumentu, se na výdeji nemusí objevit. Snippety rozšiřujeme díky strukturovaným datům o následující parametry:
Text otázky
Text odpovědi
Jak získáváme strukturovaná data pro FAQ stránky?
Strukturovaná data pro zmíněné parametry parsujeme přímo ze zdrojového kódu konkrétní stránky. Získáváme je z anotací typu schema.org/FAQPage. O zpracování dat podle standardů schema.org jsme psali v prvním dílu této série.
Jak správně vyplnit strukturovaná data?
Aby se v našem Vyhledávání strukturovaná data zobrazila, je potřeba je správně vyplnit. V ukázce kódu, který můžete přidat do zdrojového kódu své stránky, vidíte, jak nadefinovat parametry FAQ stránky. U detailu každého parametru najdete informace o tom, v jakém formátu by měl být.
Ukázka schema.org
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Co je to čistá mzda?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Čistá mzda je finální výše odměny, kterou vám každý měsíc vyplatí váš zaměstnavatel…"
}
}, {
"@type": "Question",
"name": "Jak na výpočet čisté mzdy?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Abyste se čisté mzdy mohli dopočítat, nejprve potřebujete znát svou hrubou mzdu. Od té následně odečtete 6,5 % za sociální a 4,5 % za zdravotní pojištění."
}
}, {
"@type": "Question",
"name": "Kolik činí odvody za sociální a zdravotní?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Odvody za zdravotní pojištění, které platí zaměstnanec, představují 4,5 % z měsíčního příjmu, zálohy na sociální pojištění pak činí 6,5 %. Sociální a zdravotní pojištění však musí platit i zaměstnavatelé. Pro ty je sazba o něco vyšší. Za sociální pojištění odvádějí za každého zaměstnance 24,8 % a za zdravotní 9 %."
}
}
}]
}
</script>
NÁŠ TIP: Pokud chcete jednu z odpovědí označit za nejlepší, použijte pro ni anotaci acceptedAnswer a pro ostatní suggestedAnswer.
Jak otestovat, že jste strukturovaná data vyplnili správně?
Pokud jsou strukturovaná data správně vyplněná, časem se zobrazí v našich FAQ snippetech. Správnou implementaci si můžete zkontrolovat hned přes validátor. Můžete sem zadat fragment vašeho kódu obsahující schema.org anotaci a zkontrolovat, že se detekuje anotace správného typu se správně vyplněnými parametry.
V případě, že narazíte na jakékoliv problémy se strukturovanými daty ve snippetech k FAQ stránkám, můžete nám je oznámit pomocí tlačítka “Zpětná vazba” přímo ve výsledcích vyhledávání nebo zaslat poznámku na e-mail vyhledavani@firma.seznam.cz.
Uživatelé v Česku na portálu Sauto.cz nejčastěji vyhledávají automobily spalující benzín*. Současná situace na trhu s palivy ale mnoho lidí, podle dat Seznam.cz Vyhledávání, podněcuje k většímu zájmu o elektroauta. Roste také počet dotazů na ceny benzínu, zejména na čerpacích stanicích Ono. Na Zboží.cz mají lidé větší zájem o kanystry, většinou o ty o objemu 20 litrů. Podíváme-li …
Česká internetová jednička tradičně zveřejnila svoje skokany vyhledávání – výrazy, jejichž hledanost ve srovnání s předchozím rokem vyrostla nejvíce. Mezi častěji zadané dotazy patřily ty na filmovou a seriálovou tvorbu. Konkrétně této kategorii loni kralovala česko-slovenská komedie s názvem Villa Lucia. Na čelní místo žebříčku více hledaných výrazů týkajících se volnočasových aktivit se probojovalo Námořní muzeum …
Page Quality je jedním z nejdůležitějších faktorů, které rozhodují o viditelnosti vašeho webu ve vyhledávání. Nejde jen o technickou metodu hodnocení, ale o souhrn principů, které určují, jak kvalitní, důvěryhodná a uživatelsky přívětivá vaše stránka skutečně je. Zjistěte, co vše Page Quality ovlivňuje a jak můžete její úroveň zvýšit, abyste posílili pozice svého webu v SERPu i důvěru uživatelů.
Zpracování osobních údajů
Za účelem využití služby „Newsletter Seznam.cz” dostupné na internetové adrese (URL) https://blog.seznam.cz (dále jen „Služba“) uživatelem Služby (dále jen „Uživatel“) je společnost Seznam.cz, a.s., IČO 261 68 685, se sídlem Radlická 3294/10, 150 00 Praha 5, provozovatel Služby (dále jen “Provozovatel”) oprávněna zpracovávat osobní údaje Uživatelů (zejména adresné a popisné údaje v rozsahu níže uvedeném), které tito Uživatelé poskytnou Provozovateli v rámci užívání Služby.
Osobní údaje Uživatele budou zpracovány Provozovatelem v nezbytném rozsahu za účelem poskytování Služby, a to zejména za těmito účely:
za účelem zařazení kontaktních údajů do databáze Provozovatelem a za účelem zasílání obchodních nabídek Uživateli ze strany Provozovatele;
za účelem zařazení kontaktních údajů do kontaktů Provozovatele za účelem vzájemné budoucí komunikace Provozovatele a Uživatele.
Takové zpracování osobních údajů je zákonné, jelikož je nezbytné pro splnění smlouvy, na jejímž základě Uživatel užívá Službu, a jejíchž smluvní stranou je Uživatel, jako subjekt osobních údajů.
Provozovatel postupuje při zpracování osobních údajů v souladu s nařízením Evropského parlamentu a Rady (EU) č. 2016/679 o ochraně fyzických osob v souvislosti se zpracováním osobních údajů a o volném pohybu těchto údajů (obecné nařízení o ochraně osobních údajů, dále jen „nařízení“), zákonem č. 110/2019 Sb., o zpracování osobních údajů, zákonem č. 111/2019 Sb., kterým se mění některé zákony s přijetím zákona o zpracování osobních údajů, zákonem č. 480/2004 Sb., o některých službách informační společnosti, zákonem č. 127/2005 Sb., o elektronických komunikacích a dalšími právními předpisy upravující ochranu osobních údajů.
Podrobnější informace o nakládání s osobními údaji jsou uvedeny na internetových stránkách Provozovatele, a to v příslušné sekci.